Недавно на работе произошла следующая ситуация, потребовавшая не совсем тривиальной диагностики. Есть Java-приложение, выполняющее пакетную обработку информации. Обработка выполняется последовательно в несколько стадий. Каждая стадия выполняется в нескольких потоках. Несмотря на высокую требовательность к процессорному времени, приложение не может полностью утилизировать ресурсы сервера. В чем же дело?
Довольно быстро появилась гипотеза, что дело в GC, который добавляет паузы в работу приложения и не позволяет польностью утилизировать CPU. Гипотеза согласовывалась с тем что сообщали нам jstat и JFR. Но чтобы понять как лучше оптимизировать приложение, было необходимо оценить степень влияния GC на потоки одной конкретной стадии, а не на все приложение в целом. Именно эта стадия была узким местом. Ни jstat ни JFR этого не умеют.
Как реализован stop-the-world в JVM? Link to heading
В JVM происходит много неблагодарных процессов, но пожалуй самый неблагодарный – сборка мусора. В такие моменты JVM нужно время побыть одной, подумать, побродить по heap’у. А тут, как назло, бегают другие потоки и системно мусорят. Поэтому, эти потоки надо остановить.
Для того чтобы JVM могла остановить любой поток придуман safepoint. Safepoint представляет собой точку синхронизации потоков. Это как Тюрьма в Монополии. Попав в него, поток не может ни петь, ни рисовать, ни ландыши топтать, пока JVM не решит, что можно продолжать выполнение приложения. Так и случаются те самые stop-the-world паузы.
Механика остановки потока зависит от того чем он сейчас занят. “Коня на скаку…” с x86 не получается, поэтому возможны несколько вариантов:
- поток находится в нативном коде (С/С++-коде). Такие потоки JVM не интересуют. По-крайней мере, до тех пор, пока они не взаимодействуют с Java-объектами. Пусть себе выполняются. После того как управление вернется из нативного вызова, потоку оторвет ноги аккуратно расположенной растяжкой прямо на входе в виртуальную машину;
- поток заблокирован на системном вызове. Аналогично предыдущему пункту. Хороший поток – мертвый поток.
- поток выполняет Java-код в режиме интепретации. Эти потоки мешают JVM, поэтому виртуальная машина подменяет таблицу диспетчиризации вызовов, вынуждая поток попасть на блокировку;
- поток выполняет машинный Java-код. Так как Java JIT’ит код до поросячего визга, с такими потоками дела обстоят сложнее. Механизм их блокировки должен быть не только корректным, но и шустрым, чтобы не сьесть прирост от JIT-компиляции. Safepoint в этом случае реализован через обработку сигнала
SIGSEGV, который в свою очередь инициируется прерыванием процессора. После срабатыванияSIGSEGVиспользуются уже традиционные механизмы синхронизации потоков.
Прерывание возникает при обращении к заранее определенной странице памяти, которая в нужный JVM’у момент времени становится закрытой от доступа (см. метод JDK SafepointSynchronize::begin()). Обращения эти JIT размазывает тонким слоем по всему машинному коду. На Linux-платформах блокировка страницы памяти осуществляется вызовом mprotect() к операционной системе с флагом PROT_NONE. Это запрещает какой-либо доступ к странице памяти. Так и появляется тот самый SIGSEGV.
OutOfMemoryError.Наточил я свой strace Link to heading
Поток не может быть заблокирован в user space. Это очень важная мысль, потому что она приводит нас к следующему заключению. Если поток не потребляет CPU, он заблокирован на системном вызове.
kill -SIGSTOP $PID вы можете сказать планировщику, что процессу больше процессорное время давать не надо. В этом случае, процесс формально не будет заблокирован на системном вызове, просто ему CPU не дают.Это означает, должен быть связанный с ожиданием на safepoint’е системный вызов. Это вызов обслуживающий лок используемый для блокировки потока. В нашей ОС (Linux) - это futex().
Понаблюдав за продолжительными вызовами futex() (GC по заверением jstat занимает существенно дольше 50 мс.) мы нашли адрес памяти, который используется для синхронизации на safepoint.
$ strace -e trace=futex -T -p $PID 2>&1 \
| awk -F'[ <>(),]' '$(NF-1) > 0.05 {print $2, $(NF-1)}’
0x7f747c255554 0.050588
0x7f747c255554 0.073799
0x7f747c255554 0.102169
0x7f747c255554 0.109851
...
Используя аналогичный однострочник для jstat собираем информацию о задержках по телеметрии самой JVM.
$ jstat -gccause $PID 100 \
| awk '{print $11-LAST; LAST = $11; fflush()}' \
| egrep '\.'
0.062
0.07
0.073
0.07
...
Сводим это на одном общем графике.
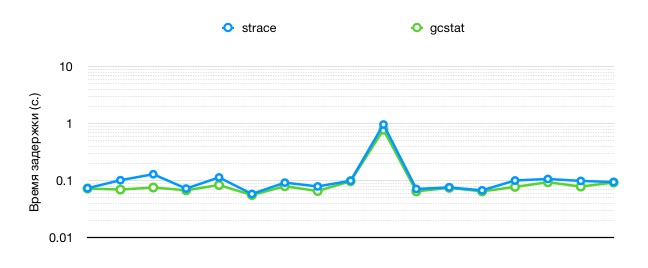
Здесь видно, что задержки рапортуемые strace несколько больше, чем те что сообщает jstat.
Что в итоге Link to heading
По итогу мы количественно определили влияние GC на конкретный поток виртуальной машины, чего невозможно сделать только встроенными в JVM средствами.
Выводы:
- очень полезно знать инструментарий диагностики ОС. Довольно тяжело сделать что-нибудь стоящее так, чтобы об этом не узнала операционная система. Это означает что инструментарий ОС предоставляет массу информации о выполняемом приложении вне зависимости от того на каком языке написано это приложение;
- диагностические инструменты конкретной платформы/ЯП могут быть подвержены системным искажениям. Эти искажения, обусловленные методом сбора информации, могут затруднить постановку диагноза пациенту. Как следствие, для некоторых метрик имеет смысл делать кросс чек. Другими словами, мерять температуру у пациента в “нескольких местах” сразу.