О новых фичах Java 8 было сказано уже довольно много. В основном обсуждают замыкания, Stream’ы, новое API для работы со временем, default-методы в интерфейсах, класс Optional и отсутствие Permanent Generation.
Но помимо жирных фич, в Java 8 сильно изменилась стандартная библиотека по перифирии. В частности, в уже существующие классы было добавлено много методов существенно упрощающих ежедневные задачи. Об этом мы сегодня и поговорим.
Итак, Top 10 самых не обсуждаемых фич Java 8. Поехали.
String.join() Link to heading
Неужто свершилось?! 2014 год на дворе, а в стандартной библиотеке Java появился метод объединяющий набор строк в одну с заданным разделителем.
String.join(", ", "A", "B", "C"); // A, B, C
Но лучше поздно чем никогда. Раньше приходилось или плясать со StringBuilder‘ом. Ну или, самый разумный вариант, использовать Guava или commons-lang.
Ещё один вариант использовать Stream<String> и Collectors.joining():
Collection<String> strings = ...;
strings.stream()
.filter(i -> i != null || i.isEmpty())
.collect(Collectors.joining(", "));
В этом случае, появляется возможность предварительно отфильтровать пустые строки.
Map.computeIfAbsent()/getOrDefault()/merge()/putIfAbsent() Link to heading
Даю голову на отсечение, если вы пишете на Java, то у вас в проекте есть код похожий на этот:
Map<String, Integer> data = ...;
for (String s : strings) {
if (!data.containsKey(key))
data.put(key, 0);
data.put(key, data.get(key) + 1);
}
Суть проста. Есть отображение из строки в счетчик, сколько раз мы встретили эту строку. Надо только не забывать инициализировать позиции Map‘а нулем, а то виртуальная машина в вас NullPointerException кинет.
В Java 8 эта же задача решается проще:
for (String s : strings)
data.merge(s, 1, (a, b) -> a + b);
Meтод merge принимает ключ, значение и функцию которая объединяет заданное значение и уже существующее в отображении, если таковое имеется. Если в отображении под заданным ключем значения нет, то кладет туда указанное значение.
Для любителей однострочников, есть вариант похардкорней:
strings.forEach(s -> data.merge(s, 1, (a, b) -> a + b));
Аналогичную функциональность, но в другом контексте, дают методы:
computeIfAbsent()– возвращает или значение из отображения по ключу, или создает его, если его не было;putIfAbsent()– добавляет значение в отображение, только если его там не было. Этот метод ранее имелся только уConcurrentMap, теперь появился и уMap‘а;getOrDefault()– название довольно красноречиво. Возвращает значение из отображения или переданное значение по-умолчанию. На мой взгляд, метод довольно не идиоматичен. Для работы с отсутствующими значениями был добавлен типOptional, его и следовало использовать. Поэтому, я бы добавил метод:Optional<V> getOptional(K key). Но кто я такой…
ThreadLocal.withInitial() Link to heading
Тех, кто плотно работает с многопоточностью, ничем не пронять. Они как ветераны Вьетнама, и даже флешбеки по ночам так же мучают. И этой конструкцией их не напугаешь:
// Java 7 и ранее
ThreadLocal<ObjectMapper> mapper = new ThreadLocal<>() {
@Override
protected ObjectMapper initialValue() {
return new ObjectMapper();
}
};
Но теперь, за счёт замыканий, стало проще:
// Java 8
ThreadLocal<ObjectMapper> mapper = withInitial(() -> new ObjectMapper());
Files.lines()/readAllLines()/BufferedReader.lines() Link to heading
В Java 8 стало возможным гораздо проще выполнить такую простую задачу как прочитать построчно файл. Это ещё одна задача, которая раньше требовала довольно много кода. Теперь так:
SummaryStatistics называется getAverage(), хотя более точным было бы имя getMean(). Термин mean описывает именно арифметическое среднее, в то время как термин average относится к понятию среднего значения в целом и может относится к любой мере центральной тенденции (арифметическое среднее, медиана, геометрическое среднее, мода и т.д.). Примечательно, что даже в документации к методу getAverage() фигурирует именно понятие mean: “Returns the arithmetic mean of values recorded”.// на входе файл в формате "одна строка - одно число"
// раcсчитываем среднее всех чисел
int mean = lines(new File("file").toPath())
.mapToInt(Integer::parseInt)
.summaryStatistics()
.getAverage();
Аналогичный метод был добавлен в класс BufferedReader, поэтому теперь Stream’ы доступны поверх любого InputStream‘а.
Парадокс Comparator’а Link to heading
Допустим вам надо написать имплементацию Comparator‘а для сортировки объектов по-возрастанию. Обычно, компаратор выглядит следующим образом:
public class ByScoreComparator implements Comparator<User> {
@Override
public int compare(User u1, User u2) {
return (int) signum(o2.getAge() - o1.getAge());
}
}
Вопрос лишь в том, что от чего надо отнимать, чтобы получить верный порядок сортировки? Наука говорит, что если вы будете выбирать вариант случайно, то угадаете примерно в половине случаев. В конце концов, варианта всего два: или от u2 отнять u1 или наоборот.
Парадокс заключается в том, что написать компаратор правильно с первого раза не получается практически никогда. Заканчивается всё всегда одинаково, — флегматичным замечанием: “Ах да, я же тут отнял неверно!”.
Благо, теперь это и не требуется. Компаратор можно собрать из говна и палок, а точнее из ссылок на методы, которые возвращают Comparable типы или примитивы по которым мы хотим сортировать.
Comparator<User> comparator = Comparator
.comparingDouble(User::getAge)
.thenComparing(User::getName);
List<User> hList = ...;
hList.sort(comparator);
PrimitiveIterator Link to heading
Одно из ограничений Java предыдущих версий заключалось в том, что в них не было стандартных итераторов над примитивными типами. Только над ссылочными. Теперь таковые появились в виде интерфейса PrimitiveIterator, а также его наследников: PrimitiveIterator.Of[Int|Long|Double]. Вместе с функциональными интерфейсами над примитивными типами это дает хорошую основу для работы с коллекциями примитивных типов без autobox’а.
List.replaceAll() Link to heading
Довольно удобный метод, который позволяет модифицировать все элементы списка. Если вы хотите список строк привести к нижнему регистру, раньше надо было писать что-то вроде:
List<String> list = ...;
for (int i = 0; i < list.size(); i++)
list.set(i, list.get(i).toLowerCase());
Или более продвинутый вариант:
ListIterator<String> i = list.listIterator();
while (i.hasNext())
li.set(i.next().toLowerCase());
Сейчас же можно сделать следующим образом:
list.replaceAll(String::toLowerCase);
Random.ints() Link to heading
Ещё одна возможность, о которой практически нет упоминаний, — это то что Random может создавать Stream‘ы случайных чисел нужного типа и диапазона:
// Выведет 10 случайных числел от 20 до 100
new Random().ints(10, 20, 100).forEach(System.out::println);
Есть методы для создания double‘ов (doubles()) и long‘ов (longs()).
LongAccumulator/LongAdder Link to heading
Два класса, которые представляют собой более производительные замены для AtomicLong. Класс LongAdder позволяет выполнять атомарные арифметические операции над типом long. LongAccumulator принимает произвольную функцию аккумуляции результатов. Эта функция принимает текущее значение, аргумент переданный в метод accumulate() и возвращает результат логического объединения (accumulate) двух значений.
// ранвосильно new LongAdder()
LongAccumulator a = new LongAccumulator((a, b) -> a + b, 0);
a.accumulate(1);
a.accumulate(2);
a.accumulate(3);
a.accumulate(4);
a.longValue(); // 10
При высоком contention’е два данных класса будут быстрее AtomicLong‘а за счёт того, что операции выполняются не над общим элементом, а над группой элементов по отдельности. Благодаря чему, “гусары не подерутся из-за женщин”.
Аналогичная пара классов есть для типа Double (DoubleAdder, DoubleAccumulator).
Java Flight Recorder Link to heading
Последнее по порядку, но не по важности, — это новые инструменты диагностики, которые предоставила Oracle в Java 8. А именно, Java Flight Recorder. Технически JFR появился в версии 7u40, но это настолько важный инструмент, что не упомянуть о нем я не могу.
Flight Recorder представляет собой инструментарий встроенный в JVM для сбора и диагностики самой виртуальной машины, а также приложений запущенных на ней. Запускается он командой jmc. У JFR есть несколько интересных особенностей:
- в зависимости от профиля собираемой информации, издержки на работу JFR могут быть очень низкими (менее 1% по утверждению Oracle, при конфигурации по-умолчанию). Это позволяет использовать этот инструмент в “боевых условиях” и под нагрузкой;
- JFR, в отличии от инструментов вроде VisualVM, может вести постоянную запись диагностической информации в ring buffer, и имеет настраиваемые политики dump’а информации на диск. Это позволяет настроить виртуальную машину таким образом, чтобы она постоянно вела диагностический лог, а сохраняла его только в случае возникновения проблем (например, при систематической нехватке CPU). Такой подход позволяет получать “черные ящики” описывающие состояние виртуальной машины и приложения непосредственно в момент проявления проблемы. До JFR единственный способ локализовать проблему был, — поймать её на production’е что называется “за руку”.
Какую информацию может собирать JFR? Её очень много, основные моменты, которые я считаю полезными:
- результаты семплинга кода (какие классы и методы заняли больше всего процессорного времени, в каких потоках);
- информация по всем GC циклам (сколько памяти было высвобождено, сколько времени заняла каждая сборка мусора);
- информация по аллокации памяти (из какого потока, класса и метода было выделено больше всего памяти, под какой тип данных выделяли больше всего памяти, скорость выделения по времени);
- информация по сетевому и дисковому вводу/выводу;
- какие Exception’ы и Error’ы были сгенерированы приложением;
- профиль блокировки потоков (какие потоки чаще всего блокируются, на каких локах/мониторах, какие потоки на момент блокировки владеют этими локами/мониторами чаще всего).
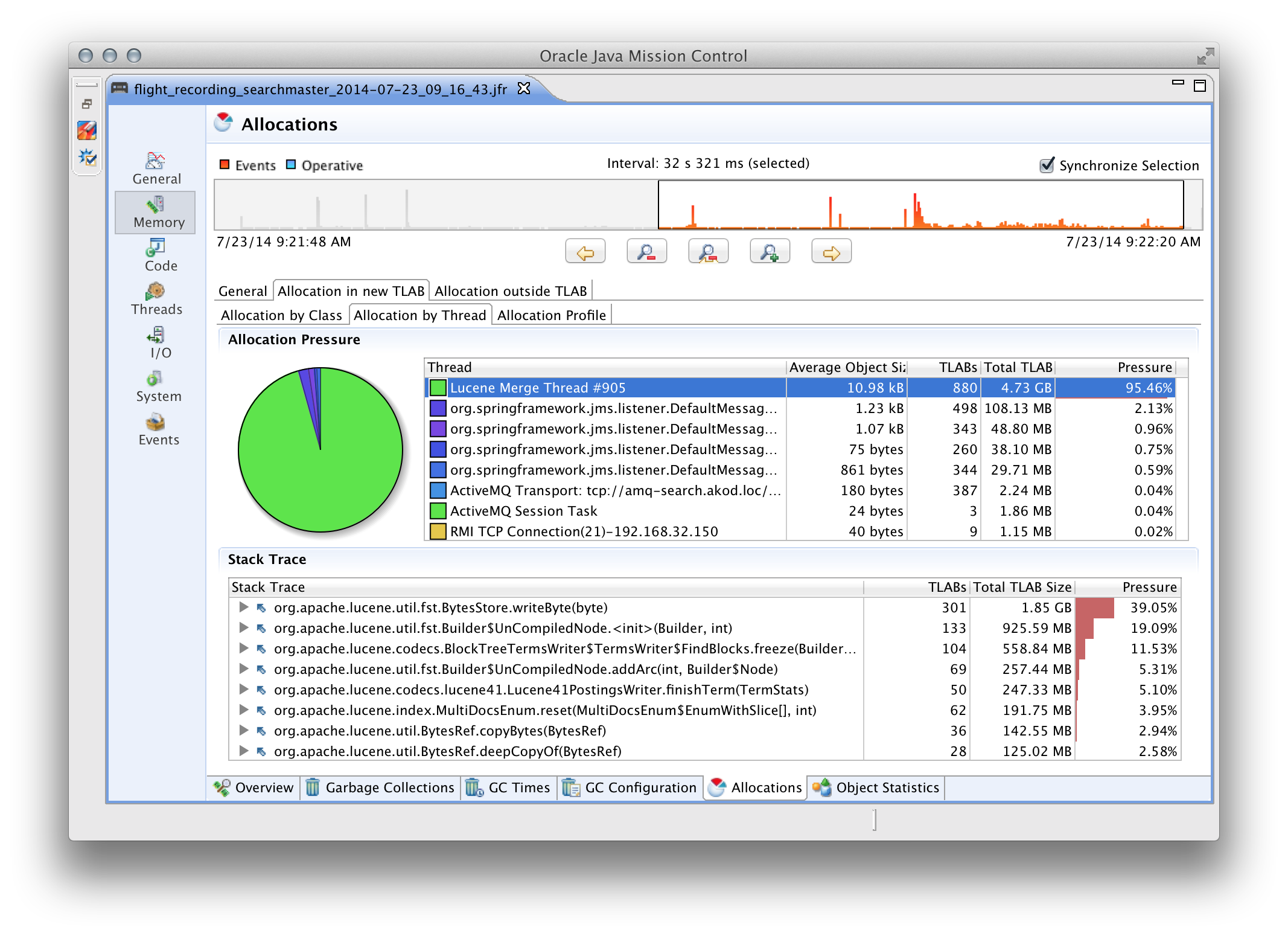
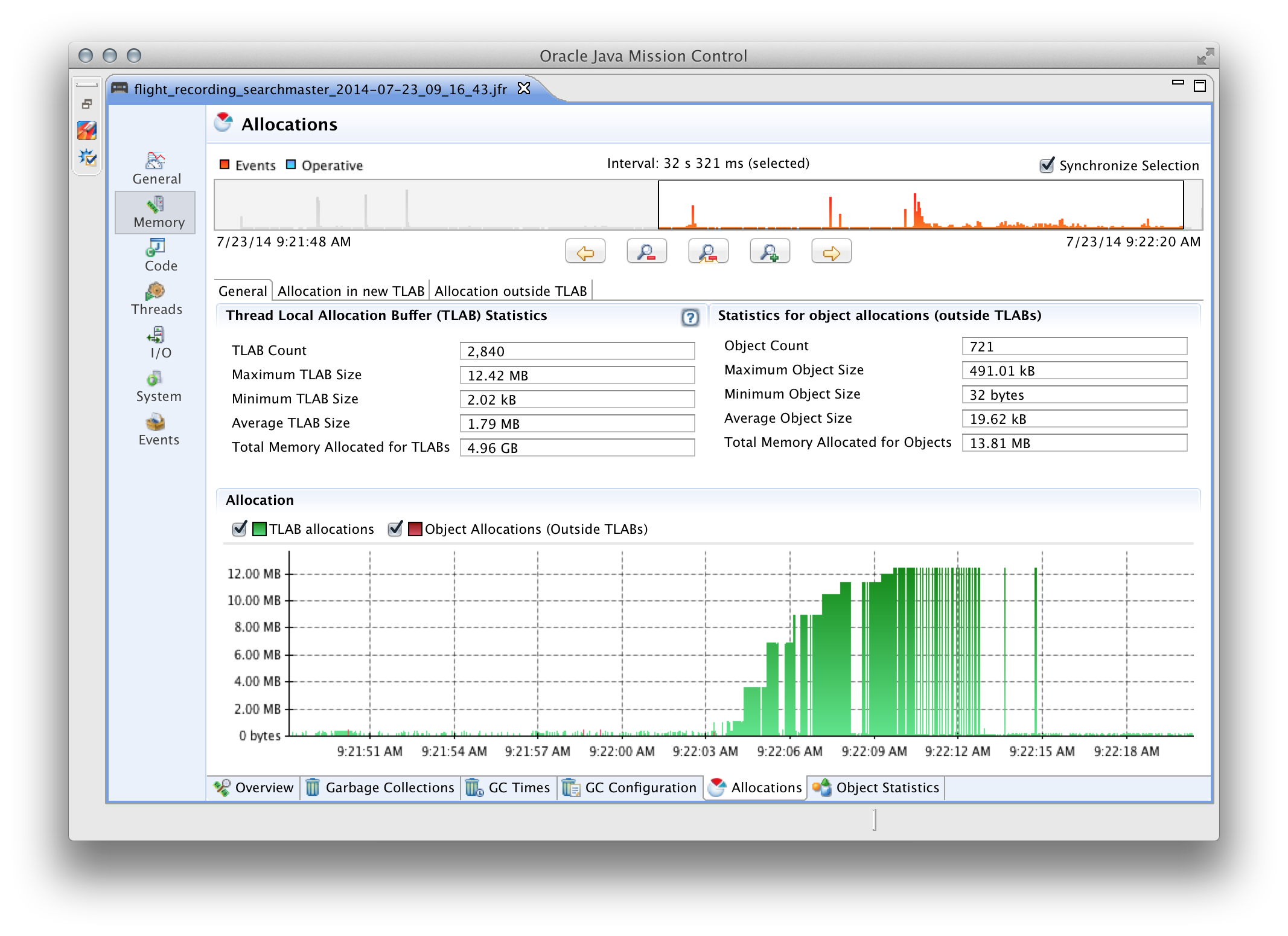
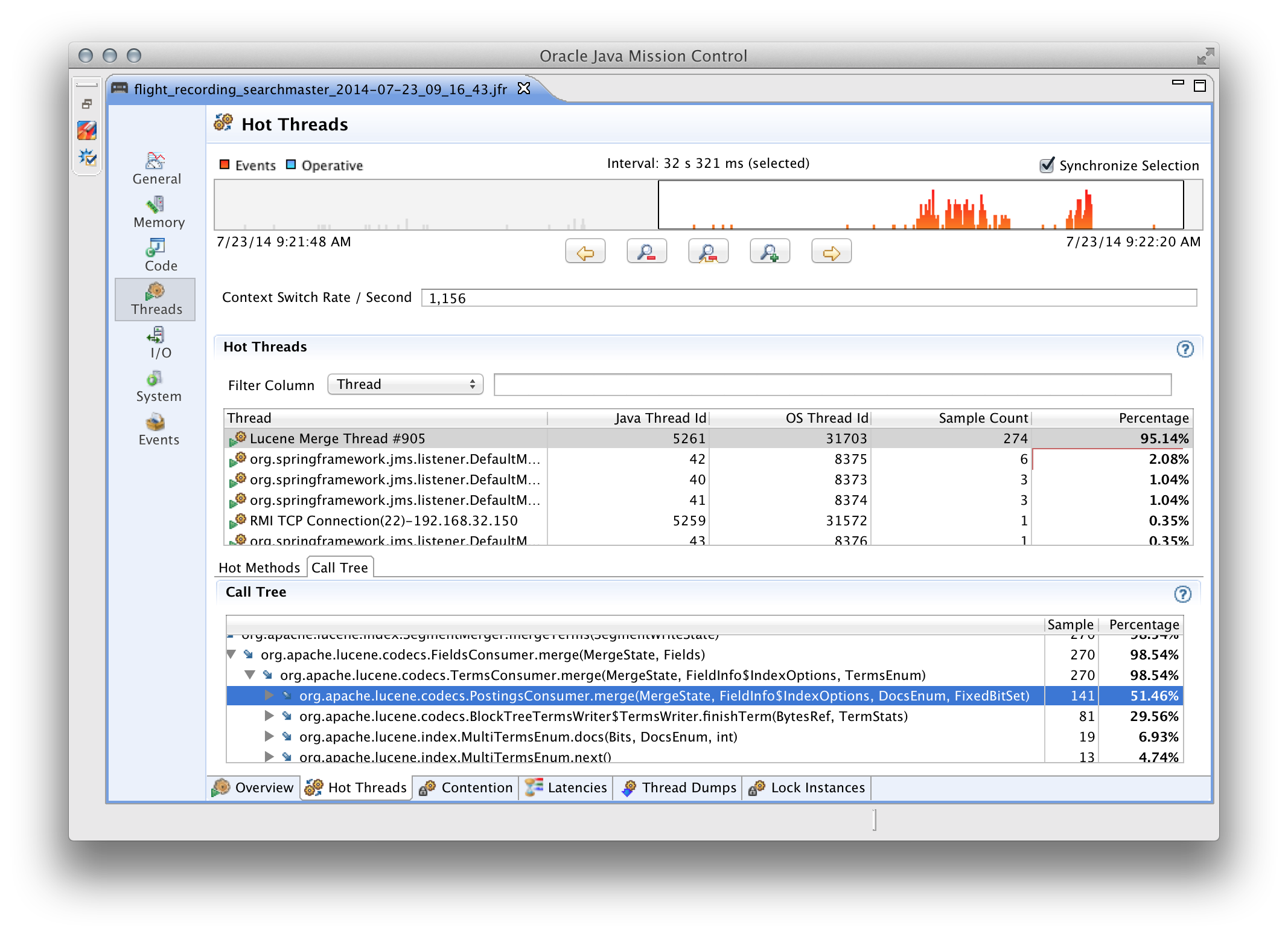
Список можно было бы продолжить, но в рамках этого поста я не смогу достаточно полно описать JFR. Поэтому, всем заинтересованым лицам настоятельно рекомендую потратить время на изучение этого крайне полезного инструмента.
Заключение Link to heading
Реальный список гораздо больше. Если вам интересно что ещё добавили в Java 8, я настоятельно рекомендую поискать по стандартной библиотеке Java следующим regexp’ом: @since\s+1.8\s*\n. Вы найдете более 1000 вхождений. Ни один блог пост этого не покроет.
Оставляйте в комментариях, какие из фич Java 8 вы используете чаще всего.