Так уж получилось, что последние несколько лет я занимаюсь вопросами, связанными с поиском. Один из проектов, завершенных в прошлом году, был связан с модифицированием архитектуры нашей поисковой системы. В итоге мы получили результаты, которыми, как я считаю, имеет смысл поделиться. So, here we go.
Функциональность поисковой системы Link to heading
Но для начала было бы неплохо конкретизировать, что именно может и для каких целей используется наша поисковая система.
На один из наших проектов каждый день заходит более сотни тысяч пользователей в поисках интересующих их товаров и услуг. Именно обслуживание этих запросов является основной задачей поисковой системы, и именно под эту задачу она и проектировалась.
Под поисковыми запросами в данном случае я понимаю не только запросы на поиск по ключевым словам, но также и атрибутивный поиск (по цене, типу товара и т.д.)
Наша система способна выполнять следующие типы запросов:
- атрибутивные (на равенство, на вхождение во множество и на вхождение в диапазон для целочисленных значений);
- полнотекстовые;
- запросы на построение фасетов.
Типичный запрос к поисковой системе выглядит следующим образом: “все автомобили производителя Toyota или Nissan, с типом трансмиссии Автоматическая, во Владивостоке, дешевле 500 000 рублей”. В дополнении к самим документам, удовлетворяющим критериям, поисковая система может вернуть фасеты. Фасет – это список значений указанного поля с указанием количества документов с этим значением поля. Типичные примеры фасетного поиска вы можете увидеть кругом в Интернете.
Также система способна выполнять сортировку (и последующий пейджинг) документов по значению одного из атрибутов или по релевантности.
Кроме того, система включает в себя более сложный функционал, который относится к информационному поиску: механизмы обработки синонимов, алгоритмы расширения пользовательского запроса для обеспечения полноты и другой функционал, о котором в пределах этой заметки я говорить не буду. Это отдельная тема.
Ретроспектива Link to heading
Когда обсуждают архитектуру систем, более важным, чем текущее состояние, на мой взгляд, является ретроспектива развития. Проблемы, которые испытывал проект в прошлом, являются одной из основных движущих сил, определяющих его будущее. Поэтому, я считаю важным рассказать, как поиск работал раньше, и какие проблемы заставили нас сделать то, что мы сделали.
Поиск работал очень просто. Все документы складывались в отдельную MySQL таблицу, по которой и осуществлялась необходимая фильтрация. Полнотекстовый поиск реализовывался встроенными средствами MySQL. От этого решения мы очень быстро ушли, так как полнотекстовый поиск в MySQL очень ограничен с точки зрения функциональности. Полнотекстовый индекс мы реализовали на Apache Lucene в виде отдельного сервиса. Во время записи данных в таблицу копия документа отправлялась в этот сервис для индексации текста. При выполнении полнотекстового поиска вычислялось пересечение результатов двух поисков (по MySQL и по Lucene), и результат отдавался клиенту.
Некоторые инкрементальные изменения в логике хранения были сделаны по ходу эксплуатации. Мы ушли от схемы одна таблица на все предметные области, так как эта таблица получалась очень разряженная (например, у сотовых телефонов нет атрибутов характерных для автомобилей и наоборот), в сторону схемы одна таблица для общих атрибутов + одна таблица на каждую отдельную предметную область. Это позволило немного сэкономить на времени выполнения full scan’ов даже не смотря на появившиеся join’ы таблиц.
В этом виде поиск проработал несколько лет. И никто бы его наверное и не трогал, но примерно в тот момент, когда количество актуальных предложений перевалило за миллион, частота возникновения различных проблем заставила нас задуматься о том, что срок жизни этого решения подходит к концу.
Проблем было несколько:
- intersect join делался путем отправки всех идентификаторов, полученных от Lucene в качестве дополнительного критерия фильтрации в MySQL. Это ставило ограничение на количество документов, которые мы принимаем к фильтрации от полнотекстового индекса, так как у MySQL есть лимит на длину SQL-запроса;
- так как вариативность условий фильтрации таблицы очень высокая, невозможно было подобрать covered index’ы для всех возможных запросов. Фактически, в наших условиях full scan’ы были неизбежны. Самым эффективным зачастую оказывался индекс, позволяющий обойти данные в порядке сортировки с фильтрацией не подходящих кортежей на лету. На первый взгляд такой обход кажется крайне не эффективным. Тем не менее, так как все запросы содержат инструкцию
LIMIT, позволяющую БД досрочно прервать выполнение запроса когда будет накоплено достаточное количество предложений, этот подход выигрывал у фильтрации по наиболее подходящему индексу и последующей сортировке; - из-за высокой вариативности запросов кеширование принципиально не влияло на latency системы, которое росло линейно с ростом датасета;
- добавление новых индексов в систему стало очень не тривиальной процедурой из-за необходимости делать блокирующий ALTER TABLE по таблице большого размера.
Таким путем мы пришли к пониманию того, что реляционная БД не может в полной мере удовлетворить наши потребности. И мы начали смотреть по сторонам. Но для начала надо было определится что именно мы хотим получить в итоге.
Основные силы, определяющие архитектуру Link to heading
Архитектура определяется потребностями, тем, какой мы хотим видеть систему в будущем, и в каком направлении мы будем ее развивать. Поэтому не лишним будет описать основные факторы, определившие созданное нами решение.
Возможность transactional и data мастшабирования Link to heading
В момент когда мы формировали облик системы, у нас уже была относительно немаленькая транзакционная нагрузка (несколько сотен поисковых запросов в секунду), и учитывая ретроспективу проекта она должна была расти с известной нам скоростью. Имеющееся у нас на тот момент решение уже было вполне способно масштабироваться по пропускной способности за счет репликации.
Но было известно также, что существенные ресурсы будут вкладываться в увеличение объема контента, поэтому нам было необходимо решение которое сможет масштабироваться не только по пропускной способности, но и по размеру корпуса документов. Репликация, к сожалению, не является адекватным решением масштабирования по объему данных.
Также мы хотели получить систему, на операционные проблемы которой (в плане нагрузки) не надо будет отвлекать программистов. Это довольно типичный синдром, нагрузка на систему вырастает, и программистам сразу же приходится бросать свои текущие задачи, чтобы вернуть систему в стабильное состояние. Нам нужна была система, в которой мы могли бы компенсировать нагрузку железом, а не временем разработчиков. Возможность компенсации железом если не решает проблему нагрузки полностью, то позволяет команде не заниматься fire fighting’ом. Она дает драгоценное время, чтобы спокойно обдумать сложившуюся ситуацию, после чего без спешки реализовать, протестировать и ввести в эксплуатацию адекватное решение.
Отказоустойчивость поиска Link to heading
Оборудование выходит из строя как планово так и внепланово, но люди должны иметь возможность искать интересующие их товары и услуги в любое время дня и ночи вне зависимости от проведения плановых работ или возникновения операционных инцидентов. Естественным ответом на эту потребность является резервирование всех жизненно важных ролей для системы. Если без какого-то звена системы поиск не возможен, это звено должно быть минимум дублировано.
Требование доступности определило важную архитектурную особенность системы, которая отличает ее от современных open source аналогов, таких как Sphinx, Solr и Elastic Search. Позже я объясню в чем она заключается.
Гибкость в реализации сценариев поиска Link to heading
Но самое главное качество поиска заключается не в его скорости, масштабируемости или отказоустойчивости, а в том, что он позволяет пользователям находить интересующие их предложения. Это не так просто как кажется на первый взгляд. Пользователи не всегда точно знают, что они ищут, равно как и не все знают как эффективно пользоваться поиском, чтобы найти нужную информацию. Иногда, они указывают слишком узкие критерии поиска и получают пустую выборку. Это ситуация из которой человеку не просто выбраться. Мы заранее знали, что нам прийдется реализовывать более экзотичные виды поиска.
Такое положение вещей диктовало дизайну и архитектуре системы еще одно требование. С точки зрения дизайна вся логика, определяющая сценарий поиска, должна соответствовать принципу OCP, чтобы ее легко можно было расширять и реализовывать новые сценарии, а архитектурно исполнение кода сценария должно быть отделено от самого индекса, над которым сценарий выполняется.
Перечисленные выше требования по большей части и сформировали архитектуру всей системы.
Существующие решения Link to heading
Конечно же в первую очередь мы смотрели на уже существующие open source решения и прикидывали, можем ли мы использовать что-нибудь готовое. Таких решений несколько: Sphinx, Solr и Elastic Search. В документации у них заявлено, что это distributed и fault-tolerant системы. На практике же и Sphinx и Solr это скорее инструменты для создания такой системы, но сами по себе они таковыми не являются.
Во-первых, ни одна из вышеперечисленных систем не сохраняет исходные документы. Это означает, что на выходе вы получаете набор идентификаторов, а не документы, которые вы отправляли на индексацию. По этой причине необходимо также обеспечивать и отказоустойчивость базы данных, в которой вы храните первичные данные. В противном случае, поиск вроде как fault-tolerant, но как только БД с первичкой становится недоступна, оказывается что система не в состоянии обслуживать поисковые запросы. По-крайней мере, в том смысле, в котором это понимает пользователь, а именно – показать документы, подпадающие под указанные критерии. Стоит отметить, что физически Solr умеет хранить данные в Lucene-индексе, но сами разработчики настоятельно не рекомендуют этого делать. Связано это в первую очередь с существенными издержками на I/O1.
Во-вторых, ни Sphinx, ни Solr не имплементируют раздельной индексации. То есть подготовки отдельных индексов для различных партиций. Документация по обоим проектам перекладывает эту ответственность на клиента2 3. Насколько мне известно, раздельную индексацию поодерживают только Elastic Search и довольно новый проект SolrCloud.
И последнее, но не менее важное. На момент принятия решения у нас уже был существенный опыт эксплуатации Apache Lucene. Он у нас использовался в тот момент для обслуживания полнотекстовых запросов. Причем опыт этот был сугубо позитивный. Lucene отлично справлялся с возложенной на него задачей, и довольно быстро появилось осознание того что область его применения гораздо более обширная, чем просто fulltext поиск.
В итоге мы решили реализовать собственный интеграционный слой поверх Apache Lucene и Berkeley DB JE в качестве БД для документов, который бы предоставил все требуемые нам возможности.
На Berkeley DB выбор пал по нескольким причинам. Предполагаемые паттерны доступа были очень простые (только по первичному ключу), поэтому мы сразу начали оценивать целесообразность применения NoSQL решения для хранения документов. Упрощенная модель данных, если подходит под задачу, при прочих равных дает целый ряд преимуществ: меньше сюрпризов с производительностью, простая диагностика проблем, относительно дешевая отказоустойчивость. Berkeley DB хорошо подошел под наши сценарии использования. Это CP система, у нее мигрирующий мастер и запись по кворуму, что позволяет и читать, и писать документы до тех пор, пока в кластере осталось хотя бы N/2+1 машин. С точки зрения диагностики потенциальных проблем этот вариант для нас тоже был предпочтительным, так как будучи встраиваемой БД мы знали что сможем контролировать гораздо больше аспектов её поведения. К тому же, так как система реализовывалась на Java, Berkeley DB JE был удобен еще и с точки зрения стоимости тестирования.
Архитектура поисковой системы Link to heading
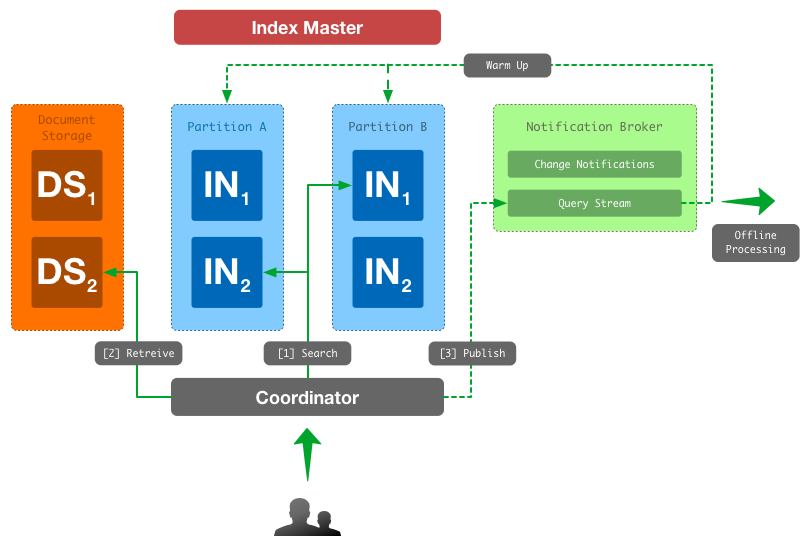
С высоты птичьего полета наша поисковая система выглядит следующим образом.
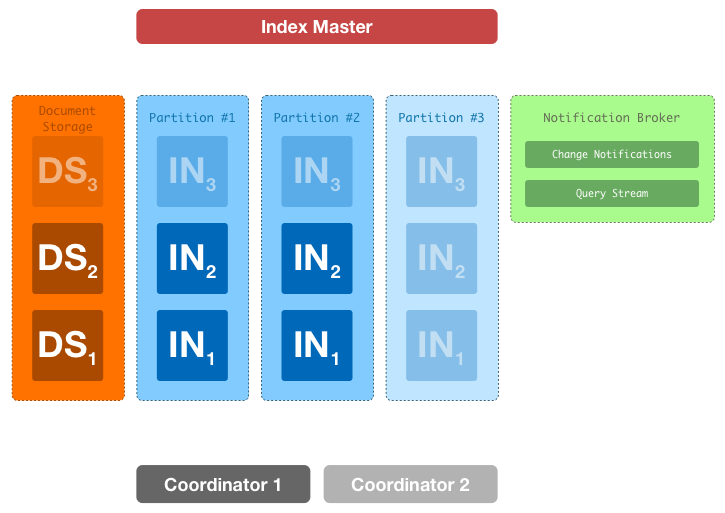
Полупрозрачным цветом обозначены звенья системы, количество которых может быть подобрано исходя из нагрузки.
Основные роли:
- Index Node (IN) — машины, выполняющие запросы над инвертированным индексом, группируются в партиции (Apache Lucene);
- Index Master (IM) — машина, обновляющая инвертированный индекс;
- Document Storage (DS) — машины занимающиеся хранением исходных документов (Berkeley DB);
- Coordinator (CN) — машины, являющиеся фасадом к поисковой системе для клиентов. Они инициируют и координируют деятельность внутри кластера, связанную с обработкой пользовательского запроса (REST-сервис);
- Notification Broker — система обмена сообщениями, которая используется нами для синхронизации состояния кластера (ActiveMQ)
Возможность transactional и data масштабирования мы реализовали путем партиционирования индекса на несколько частей и поддержанием нескольких реплик для каждой партции. Весь индекс разбивается на не пересекающиеся куски примерно одинакового размера. Каждый кусок отдается на обработку отдельной партиции. Партиция состоит из нескольких машин (реплик), которые хранят копию одной и той же части индекса и обрабатывают пользовательские запросы над этой частью индекса.
Таким образом, когда у нас появляются проблемы с транзакционной нагрузкой, мы добавляем реплики в партиции. Когда появляются проблемы с тем, что одна машина не способна эффективно обрабатывать имеющийся у нее индекс из за того что он слишком большой, мы добавляем новую партицию. При добавлении новой партиции индекс переразбивается на большее количество частей, и каждая партиция получает индекс меньшего размера.
Поиск Link to heading
Index Node’ы делают всю грязную работу, связанную с поиском. У них есть доступ к индексу, а наружу они предоставляют довольно простой интерфейс. На вход от координаторов они принимают детализированный поисковый запрос (в Lucene-формате), параметры сортировки и фасетирования, а на выходе возвращают Top N документов удовлетворяющих запросу. Такой простой интерфейс позволяет реализовывать различные поисковые сценарии, не меняя контракт взаимодействия с Index Node.
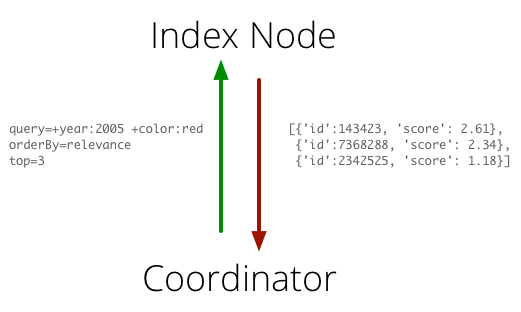
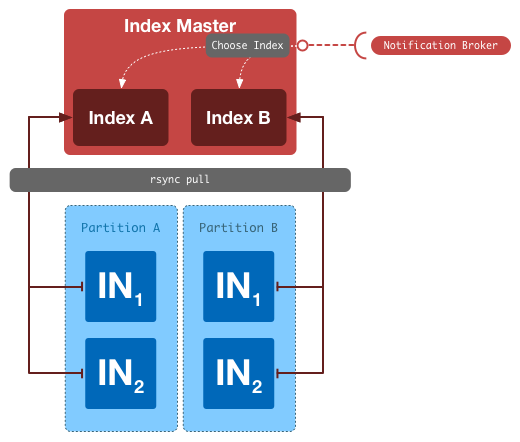
Index Node’ы периодически реплицируют индекс с Index Master’а, проверяют его целостность и делают его основным индексом, по которому выполняются поиски.
Еще одна важная деталь касающаяся Index Node’ов заключается в том, что мы разогреваем индекс перед тем как опубликовать его. Каждый Index Node имеет доступ к live потоку текущих запросов. Перед тем как пустить поисковые запросы на новый индекс, по индексу прогоняются production-запросы до тех пор, пока время ответа на этом индексе не стабилизируется. Это защищает пользователей от проблем “холодного индекса”. То же самое происходит при старте индексных машин.
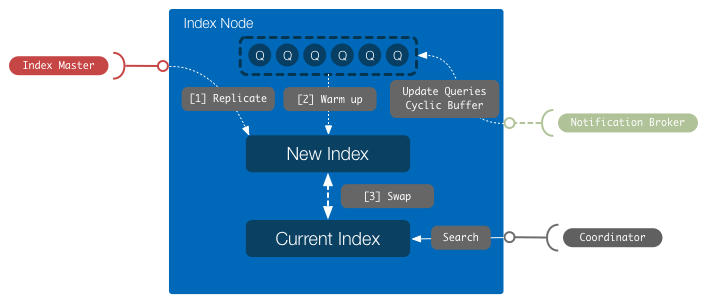
Всем процессом поиска управляют координаторы, которые тоже резервируются. При поиске координатор выбирает по одной реплике из каждой партиции и передает запрос им. После того как реплики ответят, координатор объединяет частичные результаты, полученные от реплик, выполняет пейджинг, получает необходимые документы из БД и отдает ответ клиенту. Координаторы не имеют собственного состояния и содержат всю логику, связанную со сценариями поиска.
После успешного выполнения запроса, сам запрос публикуется на общую шину для последующей обработки. Примерами такой обработки являются: архивирование логов, упомянутый ранее разогрев индекса и сбор различной статистики.
Обобщение процесса поиска проиллюстрировано на следующей схеме. Процессы, происходящие асинхронно и не блокирующие обработку поискового запроса, отображены пунктиром.
Обновление индекса и хранение данных Link to heading
Одно из решений которое, отличает нашу систему от open source аналогов вроде Solr, заключается в том, что мы храним не только индекс, но и исходные документы, которые предоставляет клиент на индексацию. Системы же вроде Solr на выходе выдают дают набор идентификаторов, и вы должны дополнительно преобразовать их в данные, которые собираетесь показать пользователю.
В качестве БД мы используем Berkeley DB Java Edition. Это key-value log-oriented база данных. Так как она является встраиваемой БД, все данные доступны in-memory, что очень удобно при умеренных размерах корпуса документов. Нагрузочное тестирование показало, что на корпусе в 50 миллионов документов BDB не является узким звеном и отлично справляется со своими задачами.
На схеме ниже отображен data-flow при записи документа в поисковую службу:
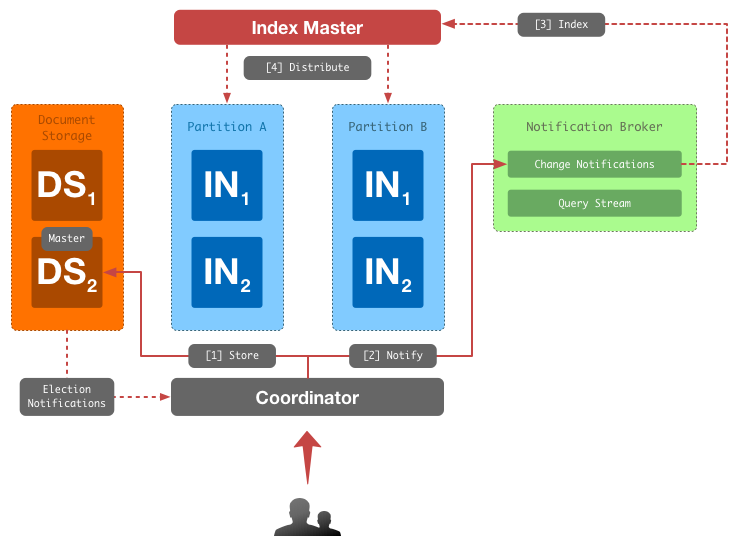
Berkeley DB периодически рапортует информацию о состоянии кластера координаторам, чтобы те знали, на какую из машин кластера отсылать запросы на запись.
Обновляется индекс отдельной машиной кластера – Index Master’ом. Структура инвертированого индекса сильно оптимизирована под эффективное чтение, поэтому его обновление операция относительно не дешёвая. В задачи Index Master’а входит:
- обновление инвертированного индекса в соответствии с поступающими на индексацию документами и топологией кластера (количеством партиций и их конфигурацией);
- поддержание индекса в компактном состоянии для минимизации накладных расходов поисковых реплик.
Именно Index Master определяет в какую партицию попадет какой документ.
Проблемы и компромиссы Link to heading
Рассказ был бы неполный, если бы я не упомянул о проблемах, с которыми нам пришлось столкнуться, и о компромиссах на которые нам пришлось пойти.
Одно из спорных решений, которое мы приняли заключается в том, что мы равномерно распределяем документы по партициям кластера на основании идентификатора документа4. Плюс этого подхода заключается, в том что мы получаем очень равномерное распределение документов и запросов, а следственно и нагрузки, между партициями. Минус же заключается в том, что этот подход не дает абсолютно никакой локализации (data locality). На фазе поиска мы не можем сделать никаких предположений о том, где расположены целевые документы, поэтому мы вынуждены опрашивать все партиции и делать scatter-gather. Это вызывает ряд неудобств.
Первое неудобство заключается в том, что координатор вынужден ждать ответа от всех партиций. Соответственно, общая производительность системы ограничивается производительностью самой медленной партиции. В случае большого количества партиций, производительность отдельной партиции может существенно отличаться от производительности системы в целом.
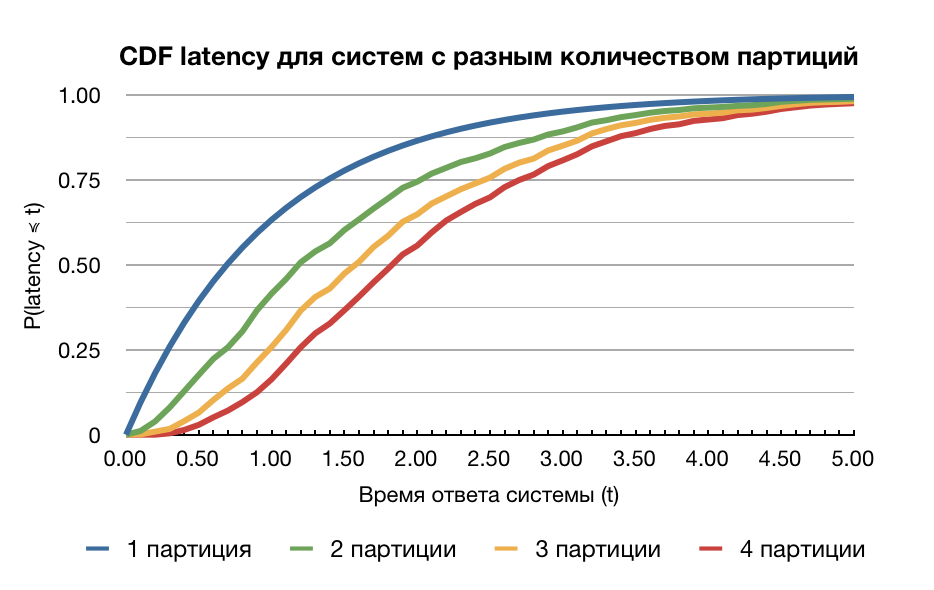
Как видно, чем больше партиций, тем ниже производительность. Если каждая отдельная партиция с вероятностью 25% отвечает за 100 миллисекунд, то система, ждущая ответа 4-х партиций, не сможет отвечать за 100 миллисекунд в 25% случаев. Следует сказать, что этот вывод основывается на предположении взаимной независимости времени ответа между партициями, что далеко не всегда является правдой. Но в распределенных системах к этому качеству всячески стремятся, так как оно полезно во многих контекстах.
Также, scatter-gather на большое количество партиций при определенных обстоятельства может приводить к моментальному выеданию сетевого канала и/или TCP-incast’у5. Суть в следующем: пейджинг можно делать только после того, как объединены поисковые результаты всех партиций. Поэтому Index Node не может делать пейджинг на своей стороне и вынужден отсылать на координатор не только страницу с запрошенными результатами, но и все документы, предшествующие ей. Таким образом, если человек запросил 1000-ую страницу, а на каждой странице по 100 документов, то каждая партиция должна отослать на координатор 100 000 совпавших документов. Легко посчитать, что при среднем размере записи в 30 байт на документ (вместе с идентификатором возвращается служебная информация) и при 10 партициях суммарный размер ответа будет близок к 30 мегабайтам. В худшем случае это означает прибавку к latency в сотни миллисекунд (на гигабитном канале) и не более 4-5 запросов в секунду на одной машинке.
С другой стороны, польза от просмотра 1000-ой страница довольно сомнительная. По нашей статистике до 10-й страницы доходит менее одного процента пользователей. Поэтому выход из этой ситуации для нас был очень простой, – мы просто не обслуживаем запросы дальше определенной страницы. Такое же поведение вы можете заметить у многих других систем (Яндекс, Google, eBay).
Еще одна причина, почему мы решили не заморачиваться с data locality, состоит в том, что в противном случае нам пришлось бы самим реализовывать Distributed IDF для Lucene6. В общих чертах, IDF — это статистическая информация по корпусу документов, которая используется для ранжирования. В случае если документы распределяются равновероятно между партициями, а не на основании их контента, мы считаем что локальный IDF партиции является приемлемой апроксимацией глобального IDF.
Вообще, схема оптимального разбиения корпуса документов – это отдельная очень большая и интересная тема, которую я не могу осветить сейчас.
Полученные результаты Link to heading
Описанная в данной заметке система работает уже около полугода, и у нас появился эксплуатационный опыт, позволяющий судить о ее качествах. Немного цифр:
- транзакционная нагрузка (номинальная 300 tps, пиковая 1000 tps, 17 миллионов запросов в сутки);
- размер текущего корпуса документов — 8 миллионов;
- пропускная способность индексации — 1000 документов в секунду;
- время ответа: среднее — 50ms, 9-й дециль — 150ms.
Система горизонтально масштабируется по размеру корпуса. Мы это проверили на практике, за последние пол года он вырос более чем в два раза. Добавление новых партиций позволило держать время ответа системы стабильным, не отвлекая от работы разработчиков.
Результаты capacity-тестирования говорят, что с минорными изменениями система способна обеспечить приемлемое время ответа на корпусе в 50 миллионов документов. По нашим оценкам, это дает нам около года спокойной работы без оглядки на проблемы с производительностью поиска, что нас вполне устраивает.