Автокомплит вещь удобная. Он позволяет экономить время на наборе текста, когда множество значений поля закрыто. Хороший автокомплит отличается следующими качествами:
- он должен быть быстрый. Если мы хотим экономить силы пользователя, то мы должны ему предложить вариант как можно быстрее;
- он не должен предлагать к вводу варианты которые заведомо неверны;
- он должен быть толерантен к пользовательскому вводу. В том числе прощать опечатки.
Вот о последнем качестве autocomplete алгоритмов я и хочу сегодня поговорить.
Если вы хотите создать приложение толерантное к вводимой пользователем информации, то исправление опечаток в том или ином виде должно быть. Человек может опечататься в первой букве, может попросту не знать как правильно пишется слово. Поэтому, не очень хорошо что первая же неверно введенная пользователем буква приведет к тому что он не сможет выбрать правильный вариант.
Я значительную часть рабочего дня провожу в IntelliJ IDEA. Отличная среда, пожалуй лучшая. А еще, я использую guava, хорошая библиотека. И есть там такой метод Closeables.closeQuietly(), который закрывает Closeable объект подавляя все исключения. Так вот, когда вы пишете имя метода которого нет в текущем классе, IDEA автоматически предлагает вам сделать static import подходящего метода из других классов.
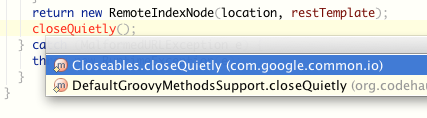
Прекрасная фича, которая не работает если вы опечатались. А я ну никак не могу запомнить как правильно пишется слово “quietly”.
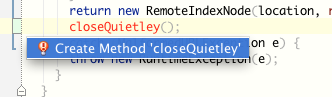
В этом случае IDE “фейлит” и предлагает мне создать новый метод. Примерно то же самое происходит и с автодополнением. Стоит мне ввести хотя бы один не тот символ, как тут же “No suggestions”. Я считаю, IDEA могла бы быть гораздо более толерантна к девелоперу на этапе ввода кода. Это же не какой-нибудь там NetBeans :)
Этой же проблемой страдает большое количество продуктов.
Такая ситуация выглядит для меня довольно странно, так как алгоритмы позволяющие разруливать большую часть опечаток при вводе довольно банальны.
Конечно, разработка первоклассного spellchecker’а дело не простое. Оно требует обучения не тривиальных статистических моделей. Но есть несколько простых подходов, которые позволяют в большинстве приложений сделать автокомплит достаточно толерантным, чтобы пользователи были счастливы в 80% случаев.
Подход №1: Редакционное расстояние Link to heading
Самое простое решение заключается в том чтобы сортировать все позиции словаря по возрастанию редакционного расстояния и показывать только первые несколько позиций. В качестве редакционного расстояния можно взять расстояние Левенштейна. Расстояние Левенштейна – это минимальное количество операций вставок/удаления/изменения символов необходимое для того чтобы преобразовать исходную строку в целевую.
Список слов близких к слову “пазор” и их редакционные расстояния:
- позор → 1
- позер → 2
- дозор → 2
- помор → 2
- побор → 2
- подзор → 2
- покер → 3
- покос → 3
Существует статистика что в пределах расстояния Левенштейна 2 находится более 90% опечаток, так что можно показывать только их, чтобы избежать совсем уж неадекватных исправлений.
Достоинства Link to heading
- довольно проста в реализации. Имплементацию расчёта расстояния Левенштейна можно найти практически для любого языка программирования.
Недостатки Link to heading
- Довольно ресурсоемкая. Алгоритмическая сложность алгоритма O(n2). Если в вашем словаре много позиций или у вас много посетителей на данное решение может не хватить аппаратных ресурсов.
- в данном виде этот подход не позволяет использовать знания о языковой модели, что не дает корректно исправлять некоторые типичные опечатки. Например опечатка “corola” находится на расстоянии 1 и от “corolla” и от “corona”, соответственно две эти замены будут равновероятны. Но пропуск дублирующей “l” гораздо более вероятная опечатка чем замена “l” на “n”.
В целом, решение на основании расстояния Левенштейна будет вполне сносно работать в первом приближении. Его очень просто реализовать, что делает данный подход отличным кандидатом на роль прототипа.
Подход №2: Коэффициент Жаккара и K-gram индекс Link to heading
Альтернативный подход заключается в том чтобы использовать коэффициент Жаккара как метрику расстояния между строками. Коэффициент Жаккара (Jaccard index) это индекс сходства двух множеств который определяется как отношение мощности пересечения этих множеств к мощности их объединения.
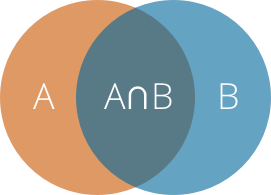
$$ J = \frac{\mid A \cap B \mid} {\mid A \cup B \mid} $$
При коэффициенте Жаккара равном 1 множества равны, при 0 не имеют ни одного общего элемента. Эту метрику можно использовать для оценки близости вводимых пользователем слов к словам из нашего словаря по которому мы делаем autocomplete.
Но для того чтобы иметь возможность расчитать коэффициент Жаккара для двух строк нам надо преобразовать их в множества. Самый простой вариант, разбить строку на символы. Но обычно берут не символы строки, а k-граммы строки (также известны как n-граммы). K-грамма – это непрерывная уникальная последовательность из k символов строки. Дублирующие k-граммы пропускают. Например, в слове “клоун” 3 триграммы (k = 3): “кло”, “лоу” и “оун”. На практике, k выбирают равным в диапазоне от двух до четырех, в зависимости от характера данных.
Cформировав из строк множество k-грамм, мы можем расчитать коэффициент Жаккара между этими строками. Например, триграммный коэффициент Жаккара для пары “corolla” и “corola” будет выше, чем для пары “corona” и “corola”. В первом случае совпадают три триграммы: “cor”, “oro” и “rol”, а во втором случае только две: “cor” и “oro”.
В контексте алгоритма автодополнения, для того чтобы иметь возможность быстро подбирать кандидатов на пользователский запрос, необходимо построить k-gram индекс по словарю автодополнения. K-gram индекс это инвертированный индекс из k-граммы в слова содержащие эту k-грамму. K-gram индекс позволяет быстро находить элементы с наиболее высоким коэффициентом Жаккара предварительно проиндексировав их.
Биграммный индекс (k = 2) для слов: “топор”, “компот” и “оптом” выглядит следующим образом:
- то → оптом, топор
- оп → оптом, топор
- по → компот, топор
- ор → топор
- ко → компот
- ом → компот, оптом
- мп → компот
- от → компот
- пт → оптом
Имея k-gramm индекс алгоритм автодополнения сводится к следующим шагам:
- разбить на k-граммы строку введенную пользователем;
- для каждой k-граммы получить список слов в которых она встречается (posting list);
- сделать merge posting list’ов с подсчетом какое количество раз каждое слово встречается в них. По факту это количество совпавших k-грамм между строкой пользователя и позицией словаря.
- отсортировать этот список по убыванию количества совпавших k-грамм;
- вернуть первые N позиций пользователю.
Достоинства Link to heading
- данная подход позволяет эффективно находить строки синтаксически близкие к целевой (с максимальным количеством пересекающихся k-грамм). Существенно быстрее чем редакционное расстояние.
Недостатки Link to heading
- как и редакционное расстояние, не позволяет использовать информацию языковой модели, что не позволяет исправлять сложные типы опечаток;
- более сложна в реализации чем подход с редакционным расстоянием.
Tips & tricks Link to heading
Некоторые замечания которые могут быть полезны, если вы захотите имплементировать толерантный автокомплит.
- K-gram индекс можно хранить в любой удобной для вас inverted index системе. Например, Apache Lucene;
- подходы №1 и №2 не являются взаимоисключающими. Очень часто K-gram индекс из за его эффективности используют как предварительный фильтр для других, более сложных алгоритмов;
- может иметь смысл предварительно убирать из текста все символы не несущие смысловой нагрузки. Например, дефисы, слэши и т.д;
- при построении k-gram из слова/фразы имеет смысл добавить в исходную строку какой-нибудь специальный символ (например, “$”) на границе слов. Это сделает результаты более точным, за счет дополнительной совпадающей k-граммы на границах.
В заключениe Link to heading
Мы рассмотрели два основных инструмента которые позволяют находить и исправлять опечатки. Они могут быть использованы как в чистом виде, так и в составе более сложных стратегий автодополнения. Надеюсь, эта информация даст вам общее представление о том как сделать более толерантное к опечаткам автодополнение.