Продолжая тему реализации автоматической классификации необходимо обсудить следующий очень важный вопрос. Как оценивать качество алгоритма? Допустим, вы хотите внести изменения в алгоритм. Откуда вы знаете что эти изменения сделают алгоритм лучше? Конечно же надо проверять алгоритм на реальных данных.
Тестовая выборка Link to heading
Основой проверки является тестовая выборка в которой проставлено соответствие между документами и их классами. В зависимости от ваших конкретных условий получение подобной выборки может быть затруднено, так как зачастую ее составляют люди. Но иногда ее можно получить без большого объема ручной работы, если проявить изобретательность. Каких-то конеретных рецептов, к сожалению, не существует.
Когда у вас появилась тестовая выборка достаточно натравить классификатор на документы и соотнести его решение с заведомо известным правильным решением. Но для того чтобы принимать решение хуже или лучше справляется с работой новая версия алгоритма нам необходима численная метрика его качества.
Численная оценка качества алгоритма Link to heading
Accuracy Link to heading
В простейшем случае такой метрикой может быть доля документов по которым классификатор принял правильное решение.
$$Accuracy = \frac{P}{N}$$
где, $P$ – количество документов по которым классификатор принял правильное решение, а $N$ – размер обучающей выборки. Очевидное решение, на котором для начала можно остановиться.
Тем не менее, у этой метрики есть одна особенность которую необходимо учитывать. Она присваивает всем документам одинаковый вес, что может быть не корректно в случае если распределение документов в обучающей выборке сильно смещено в сторону какого-то одного или нескольких классов. В этом случае у классификатора есть больше информации по этим классам и соответственно в рамках этих классов он будет принимать более адекватные решения. На практике это приводит к тому, что вы имеете accuracy, скажем, 80%, но при этом в рамках какого-то конкретного класса классификатор работает из рук вон плохо не определяя правильно даже треть документов.
Один выход из этой ситуации заключается в том чтобы обучать классификатор на специально подготовленном, сбалансированном корпусе документов. Минус этого решения в том что вы отбираете у классификатора информацию об отностельной частоте документов. Эта информация при прочих равных может оказаться очень кстати для принятия правильного решения.
Другой выход заключается в изменении подхода к формальной оценке качества.
Точность и полнота Link to heading
Точность (precision) и полнота (recall) являются метриками которые используются при оценке большей части алгоритмов извлечения информации. Иногда они используются сами по себе, иногда в качестве базиса для производных метрик, таких как F-мера или R-Precision. Суть точности и полноты очень проста.
Точность системы в пределах класса – это доля документов действительно принадлежащих данному классу относительно всех документов которые система отнесла к этому классу. Полнота системы – это доля найденных классфикатором документов принадлежащих классу относительно всех документов этого класса в тестовой выборке.
Эти значения легко рассчитать на основании таблицы контингентности, которая составляется для каждого класса отдельно.
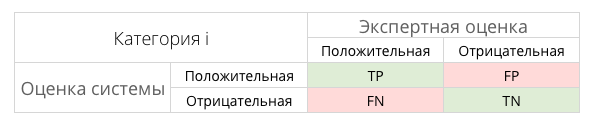
В таблице содержится информация сколько раз система приняла верное и сколько раз неверное решение по документам заданного класса. А именно:
- $ TP $ — истино-положительное решение;
- $ TN $ — истино-отрицательное решение;
- $ FP $ — ложно-положительное решение;
- $ FN $ — ложно-отрицательное решение.
Тогда, точность и полнота определяются следующим образом:
$$ Precision = \frac{TP}{TP+FP} $$
$$ Recall = \frac{TP}{TP+FN} $$
Confusion Matrix Link to heading
На практике значения точности и полноты гораздо более удобней рассчитывать с использованием матрицы неточностей (confusion matrix). В случае если количество классов относительно невелико (не более 100-150 классов), этот подход позволяет довольно наглядно представить результаты работы классификатора.
Матрица неточностей – это матрица размера N на N, где N — это количество классов. Столбцы этой матрицы резервируются за экспертными решениями, а строки за решениями классификатора. Когда мы классифицируем документ из тестовой выборки мы инкрементируем число стоящее на пересечении строки класса который вернул классификатор и столбца класса к которому действительно относится документ.

Как видно из примера, большинство документов классификатор определяет верно. Диагональные элементы матрицы явно выражены. Тем не менее в рамках некоторых классов (3, 5, 8, 22) классификатор показывает низкую точность.
Имея такую матрицу точность и полнота для каждого класса рассчитывается очень просто. Точность равняется отношению соответствующего диагонального элемента матрицы и суммы всей строки класса. Полнота – отношению диагонального элемента матрицы и суммы всего столбца класса. Формально:
$$Precision_c = \frac{A_{c,c}}{\sum_{i=1}^n A_{c,i}}$$
$$Recall_c = \frac{A_{c,c}}{\sum_{i=1}^n A_{i,c}}$$
Результирующая точность классификатора рассчитывается как арифметическое среднее его точности по всем классам. То же самое с полнотой. Технически этот подход называется macro-averaging.
F-мера Link to heading
Понятно что чем выше точность и полнота, тем лучше. Но в реальной жизни максимальная точность и полнота не достижимы одновременно и приходится искать некий баланс. Поэтому, хотелось бы иметь некую метрику которая объединяла бы в себе информацию о точности и полноте нашего алгоритма. В этом случае нам будет проще принимать решение о том какую реализацию запускать в production (у кого больше тот и круче). Именно такой метрикой является F-мера1.
F-мера представляет собой гармоническое среднее между точностью и полнотой. Она стремится к нулю, если точность или полнота стремится к нулю.
$$F = 2 \frac{Precision \times Recall}{Precision + Recall}$$
Данная формула придает одинаковый вес точности и полноте, поэтому F-мера будет падать одинаково при уменьшении и точности и полноты. Возможно рассчитать F-меру придав различный вес точности и полноте, если вы осознанно отдаете приоритет одной из этих метрик при разработке алгоритма.
$$F = \left(\beta^2+1\right)\frac{Precision \times Recall}{\beta^2 Precision + Recall}$$
где $\beta$ принимает значения в диапазоне $0<\beta<1$ если вы хотите отдать приоритет точности, а при $\beta > 1$ приоритет отдается полноте. При $\beta = 1$ формула сводится к предыдущей и вы получаете сбалансированную F-меру (также ее называют F1).
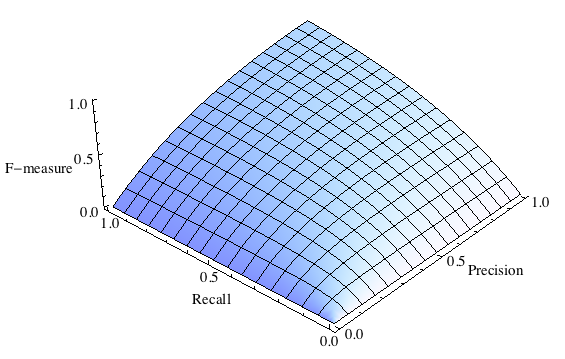
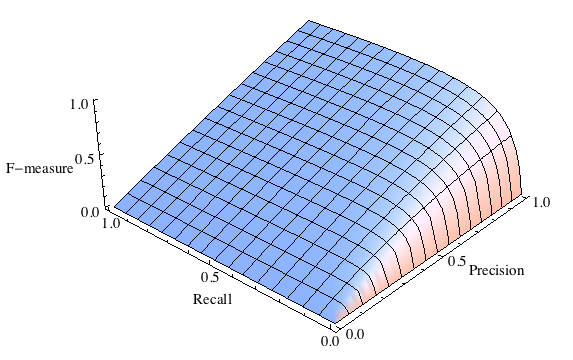
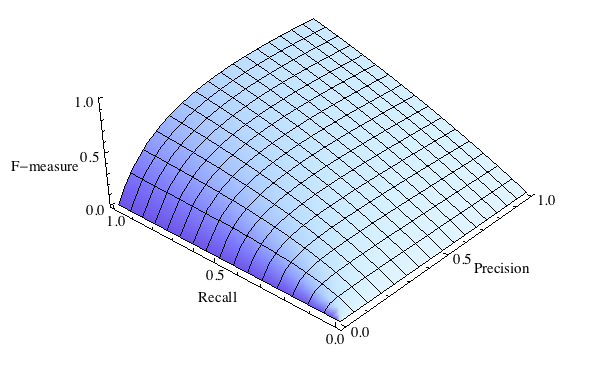
F-мера является хорошим кандидатом на формальную метрику оценки качества классификатора. Она сводит к одному числу две других основополагающих метрики: точность и полноту. Имея в своем распоряжении подобный механизм оценки вам будет гораздо проще принять решение о том являются ли изменения в алгоритме в лучшую сторону или нет.
Ссылки по теме Link to heading
- Evaluation methods in text categorization
- Micro and macro average of precision
- Информационный поиск: Оценка эффективности — Wikipedia
- Precision and Recall — Wikipedia
- Classifier performance evaluation
иногда встречаются названия: F-score или мера Ван Ризбергена. ↩︎