Сегодня я хочу обсудить следующую проблему. Как мониторить CPU usage на многопроцессорной машине? Конечно же мониторить метрики выдываемые mpstat. Эта программа выдает процент времени который процессор проводит в различных состояниях (user, system, iowait, idle и т.д.).
$ mpstat 1
Linux 2.6.32-200.13.1.el5uek (search-personal2.vfarm.loc) 05/05/2012 _x86_64_ (16 CPU)
11:35:52 AM CPU %usr %nice %sys %iowait %irq %soft %steal %guest %idle
11:35:53 AM all 8.34 0.00 0.59 0.06 0.00 0.12 0.00 0.00 90.89
11:35:54 AM all 7.27 0.00 0.86 0.00 0.00 0.36 0.00 0.00 91.51
11:35:55 AM all 7.80 0.00 0.45 0.06 0.00 0.17 0.00 0.00 91.53
11:35:56 AM all 5.33 2.17 0.84 0.00 0.00 0.14 0.00 0.00 91.52
11:35:57 AM all 5.92 0.00 0.40 0.06 0.00 0.06 0.00 0.00 93.57
11:35:58 AM all 4.71 0.07 0.42 0.00 0.00 0.14 0.00 0.00 94.67
В ретроспективе это выглядит следующим образом:
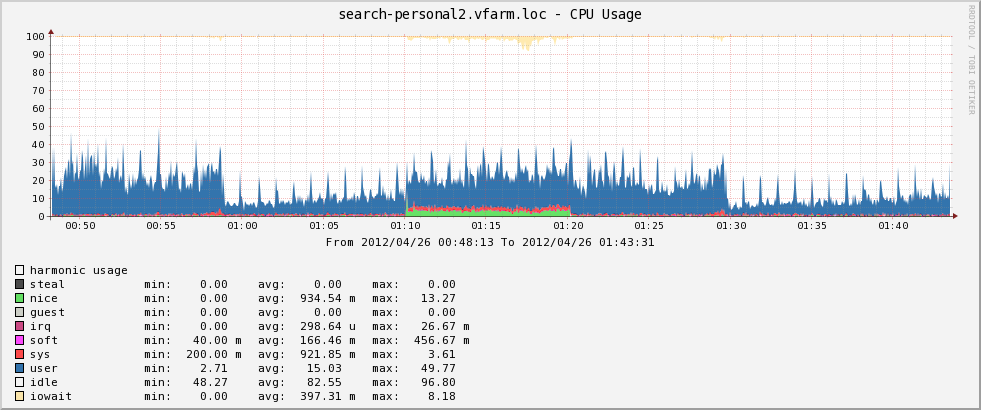
Может показаться что у этого сервера нет никаких проблем с CPU. Тем не менее надо учитывать что машина многопроцессорная и может оказаться что нагрузка на ядра не симмитрична. mpstat же показывает арифметическое среднее, поэтому если вы на 16 процессорной машине видите CPU utilization 6% это может означать:
- машина загружена симметрично и у каждого ядра есть еще масса свободного времени;
- машина загружена не симметрично – одно ядро работает на 100%, а все остальные курят бамбук.
Конечно же последний случай это явная проблема и система мониторинга должна позволять находить такие ситуации. Но что мониторить чтобы находить ассиметричную нагрузку на различные ядра?
Мониторинг Link to heading
Load average Link to heading
Load average (uptime, w) не позволяет отследить подобную ассиметричность в нагрузке, так как ее следствием является работа, которая не может быть выполнена параллельно. В этом случае в системе не будет длинной очереди CPU scheduler’а, а это именно то что и показывает load average.
Мониторить отдельно каждое ядро Link to heading
Можно отслеживать ассиметричность имея информацию по CPU usage для каждого отдельного ядра (на подобии той которая приведена в начале заметки). Но это, как вы можете догадаться довольно напряжно. Слишком много данных, которые надо пропустить через мозг чтобы получить информацию.
Экстремальные значения CPU utilization Link to heading
Можно мониторить например максимальное значение CPU utilization. Это позволит понять какая утилизация у самого загруженного ядра в системе. Благодаря этому можно отследить ситуацию ассиметричной нагрузки по разнице между арифметическим средним и максимальным значением утилизации.
Мы мониторим гармоническое среднее. Гармоническое среднее, в отличии арифметического стремится к нулю когда хотя бы одно из значений стремится к нулю. Считается оно тоже довольно просто — количество значений деленное на сумму обратных значений:
$$\frac{n}{\sum\limits_{i=1}^n \frac{1}{x_i}}$$
То есть для двух процессоров idle которых равен 3 и 100, гармоническое среднее равно: $$\frac{2}{\frac{1}{3} + \frac{1}{100}} \approx 5.8$$
Если добавить на график который я привел выше, гармоническое среднее утилизации, то мы получим следующее:
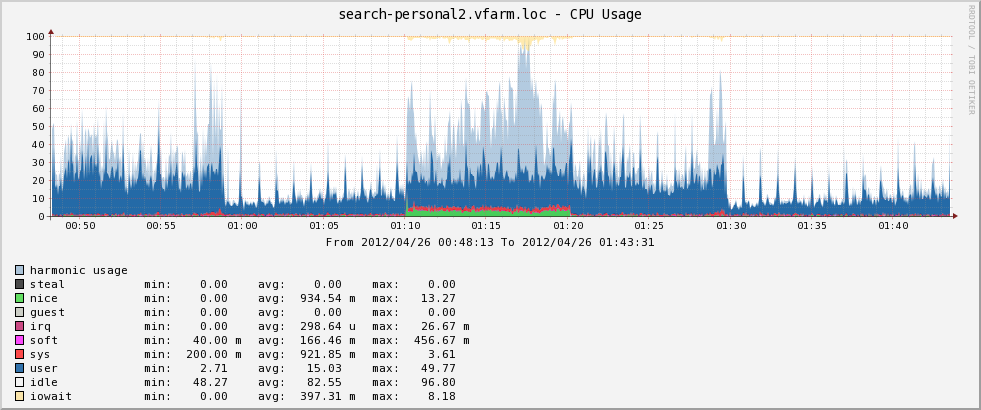
Здесь видно что большую часть времени нагрузка распределяется равномерно (светло синей области практически не видно). Тем не менее в период с 1:10 до 1:20 нагрузка на CPU ассиметрична, что говорит о выполнении задачи которая не может быть распараллелена.
Что может быть причиной? Link to heading
Это может быть любая активность которая не может быть эффективно распараллелена. Например, банальный grep по большому объему данных (если он не упрется в I/O), сжатие, потоковое кодирование видео, шифрование, некоторые алгоритмы GC в JVM однопоточные по своей природе.
Более подробно об этом явлении я уже писал ранее в заметке “Конец эры закона Мура”.
/proc/interrupts и в графы %irq и %soft вывода mpstat. На системах с высокой сетевой или дисковой нагрузкой может быть довольно большое число прерываний на одном ядре.Что делать в этой ситуации? Link to heading
Во-первых, надо понять является ли это проблемой. Вполне возможно, что эта ситуация может быть вызвана какой-нибудь background задачей, которая ни коим образом не затрагивает пользователей. Если же данная ситуация влияет на качество сервиса предоставляемого пользователям, то определенно надо более точно локализовать проблему и попытаться разрешить ее.
На ОС Linux в диагностике подобного рода проблем вам могут помочь следующие инструменты:
- команда
pidstat -u -t -p $PID 1позволяет выяснить какие потоки указанного процесса кушают CPU наиболее активно. Эта команда может быть использована в том числе и для диагностики проблем JVM приложений, так как потоки JVM напрямую соотносятся с потоками ОС; - для получения информации по потокам JVM может быть полезна команда
jstack $PID, которая делает thread dump JVM приложения (jstackявляется частью JDK и не входит в комплект поставки JRE); - для получения трейса конкретного потока можно воспользоваться командами
strace/ltrace. Они показывают трейс системных вызовов и библиотечных вызовов соответственно.
Надеюсь эти инструменты помогут вам диагностировать подобные ситуации быстро и безболезненно.