Помните фильм “Пятый элемент”? Там была сцена, когда Зорг опрокидывает стакан на пол и роботы тут же начинают уборку помещения. Всего лишь одно маленькое действие привело в жизнь десяток машин, которые сразу же начали подметать и мыть полы, а в конце еще и налили воды хозяину.
Что-то похожее происходит в коллективе с налаженным build процессом, когда разработчик коммитит изменения в систему контроля версий.
О пользе налаженного процесса билда известно много. Но “путь на production” не прост. После того как код написан и перед тем как он будет запущен на production’е было бы неплохо сделать следующие вещи:
- откомпилировать код если вы используете компилируемый язык (удивил, да?);
- прогнать модульные и интеграционные тесты если они у вас есть;
- выполнить статический анализ кода и/или другие проверки которые позволяет выполнить ваша платформа и которые имеют смысл для вашей команды (code style check, code coverage, цикломатическая сложность, dependency matrix и т.д.);
- собрать артефакт приложения (желательно в виде одного файла), содержащий в себе весь код и ресурсы необходимые для запуска приложения на целевой платформе;
- выполнить приемочное тестирование, если оно у вас есть;
- опубликовать артефакт в репозитории (предположительно локальном), чтобы другие члены комманды могли им воспользоватся в своих целях (особенно актуально, если вы разрабатываете билиотеку, а не приложение);
- в случае если вы разрабатываете приложение а не библиотеку, произвести deploy в окружение staging тестирования чтобы команда и менеджеры могли оценить текущее состояние проекта.
Этот список действий не догма и варьируется от потребностей проекта. Я же расскажу что и как делаем мы. Сразу отмечу что у нас в проекте используется две платформы: PHP и Java. Я преимущественно буду описывать как мы собираем Java проекты, так как за счет поддержки инструментария билд процесс там получается более целостный и вразумительный. Я думаю, этот опыт будет полезен читателям.
Итак код закоммичен в систему контроля версий. С этого момента начинается его маленькое путешествие на production. Но для начала давайте познакомимся с главными героями. Для того чтобы успешно проводить автоматизированною сборку проекта необходим определенный инструментарий.
В главных ролях Link to heading
Система контроля версий (VCS) Link to heading
Какую VCS систему использовать решать вам. Это может быть старый проверенный временем subversion, или модно-распределенный git/mercurial. Но она должна быть. Если на вашем календаре уже 2011 год и вы все еще не пользуетесь какой-либо системой контроля версий, то я настоятельно советую вам переоценить принципы согласно котрым вы принимаете решения.
В контексте обсуждения процесса сборки выбор системы контроля версий настолько неважен, что я даже не буду говорить какую используем мы :)
Система сборки проектов (build tool) Link to heading
Основная задача системы сборки состоит в автоматизации задач связанных с созданием релиза из исходных кодов. Среди программистов работающих с интепретируемыми языками распространено мнение что исходный код и есть релиз. Связано это судя по всему с тем, что в таких языках нет выделенной фазы компиляции. Я считаю, что даже в этом случае разделение между исходниками и релизами нужно, потому что вне зависимости от того на каком языке программирования написано приложение, релиз должен обладать следующими свойствами, которыми не обладают исходные коды:
- любой релиз в отличии от исходных кодов должен работать. Подтверждатся это должно каким-либо видом тестирования (хотя бы ручным). Исходные коды же могут находится некоторое время в нерабочем состоянии (например, во время рефакторинга);
- релиз может содержать third party библиотеки и программное обеспечение, которое разрабатывается и поддерживается третьими лицами. Хранить все это в системе контроля версий может быть не самым удобным решением;
- платформа на которой работает приложение может иметь ограничения на формат релиза. Например, может быть строго определен формат архива с приложением (например, rpm или deb). Хранить исходные коды в VCS в том же формате может быть очень неудобно c точки зрения разработки.
Выражаясь математически: релиз = ƒ(исходники).
Для сборки мы используем Apache Maven, – это довольно зрелая и продвинутая система сборки, которая впрочем не так проста в изучении как ее более “легковесные” братья вроде ant и gradle (хотя ant — это скорее бабушка, а gradle внучатый племянник). Gradle в последнее время получил довольно много положительных отзывов и продолжает набирать популярность, поэтому вам определенно стоит посмотреть на него, если вы определяетесь с вопросом выбора системы сборки Java-проекта.
Для того чтобы использовать maven более эффективно, у нас есть определенная экосистема для его поддержки.
Во-первых, это репозиторий артефактов о котором я расскажу ниже.
Во-вторых, у нас есть общий POM-дескриптор для всех проектов компании, который определяет настройки компилятора, сразу делает доступными библиотеки повсеместно используемые в нашей компании (TestNG, hamcrest, logback и т.д.), а также настраивает плагины для статического анализа кода и логгирования и т.д.
В третьих, у нас есть несколько прототипов проектов (archetype в терминологии maven), которые позволяют одной командой из консоли создать новый проект. Эдакий hello world с уже настроенным логированием, Jetty для тестирования, ActiveMQ и Spring Integration для обработки сообщений, Spring в качестве web-framework’а и много еще чем. Все это очень сильно упрощает старт, особенно людям не знакомым с премудростями настройки всего этого “зоопарка”.
Репозиторий артефактов Link to heading
Еще один вопрос связанный с системой билда — куда ложить его результат? После того как мы собрали приложение и протестировали его, нам надо опубликовать релиз. Необходимо общее централизованное место где бы хранились все артефакты, чтобы любой разработчик знал где искать последний релиз продукта. Позже вы можете достать его и использовать для deploy’я на production или в окружение staging тестирования. Если вы разрабатываете библиотеку то релиз нужен другим членам команды, для того чтобы использовать ее в своем приложении.
В простейшем случае роль репозитория может играть web-сервер. Его настройка для этих задач не займет у вас много времени. Либо это может быть FTP-сервер или сетевой диск доступный всем разработчикам. Так же эту роль может играть continious integration сервер, речь о котором пойдет ниже.
В более сложных случаях удачным решением может быть специализирванное ПО. Особенно это актуально если вы используете Maven, который специфицирует формат репозиториев и протокол работы с ними (поверх HTTP).
Мы используем Artifactory в качестве репозитория, который выполняет несколько ролей в нашей экосистеме:
- хранит артефакты делая их (и их исходники) доступными для использования любым программистом в любое время;
- кеширует third party библиотеки используемые программистами. Если вы начинаете новый проект и хотите использовать какую-то библиотеку, с высокой долей вероятности она уже есть в локальном репозитории и вы получите ее моментально не дожидаясь загрузки из интернета.
Continuous Integration сервер Link to heading
Не смотря на грозное название, CI-сервера по своей сути — это триггеры билд процесса которые предоставляют разработчикам удобный способ контроллировать процесс и результат сборок. Они делают несколько вещей:
- позволяют конфигурировать политику запуска сборки (при коммите в VCS, через заданные интевалы времени, после успешной сборки зависимого проекта, вручную, и т.д.);
- предоставляют возможность следить за процессом сборки публикуя ее логи через web-интерфейс;
- предоставляют отчеты по результатам билда (проваленные тесты, предупреждения статического анализатора и т.д.);
- строят тренды на основании истории сборок (количество тестов, время затраченное на исправление билда, процент успешных сборок и т.д.);
- могут успешно играть роль репозитория артефактов.
Строго говоря использование CI-сервера не обязательно. Более того, на начальных этапах я бы рекомендовал делать сборки на машинах разработчиков. Это позволит сэкономить вам время в процессе допиливания build-процесса, которое на начальных стадиях неизбежно.
Мы до сих пор не используем CI-сервер для сборки билиотек. Библиотеки собираются и релизятся самим программистами. Несмотря на то что этот подход имеет ряд недостатков, он существенно проще.
В качестве CI-сервера мы используем TeamCity, бесплатной версией которой мы полностью довольны. Одна из привлекательных фич этого продукта состоит в том что он предоставляет неплохую статистику по билдам, включая success rate сборок, количество тестов и т.д.
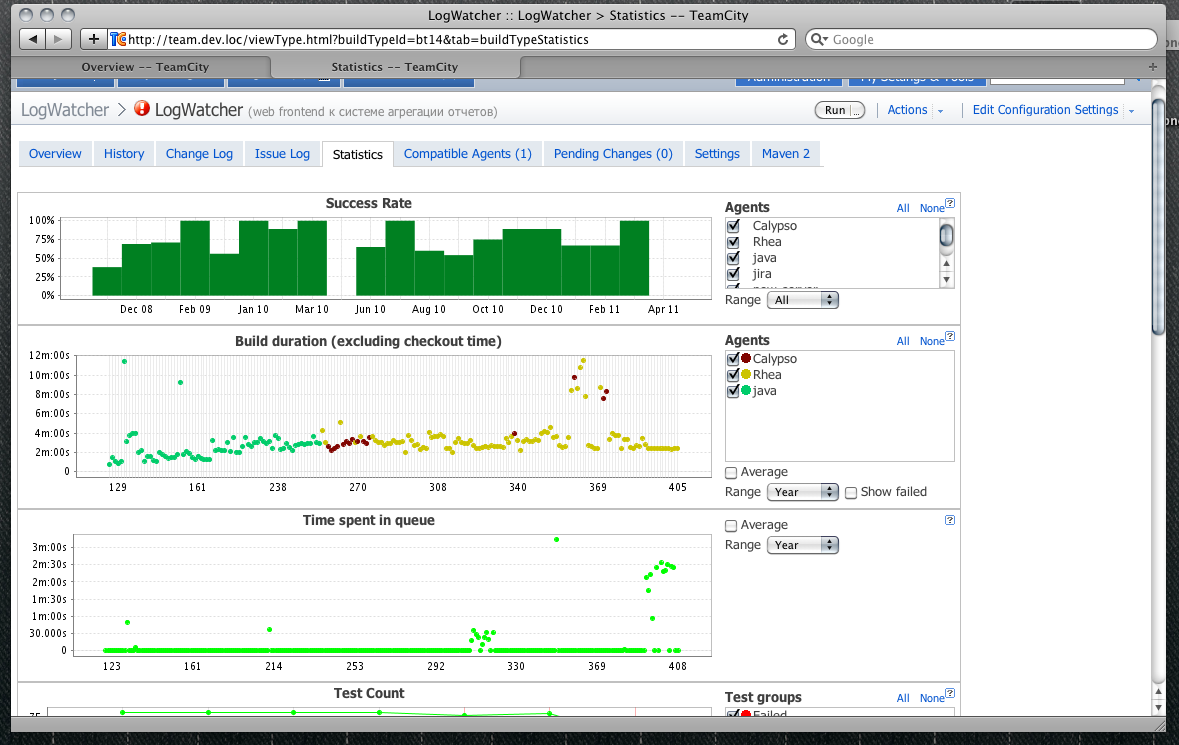
Поезд отправляется Link to heading
Итак как это все происходит на практике.
За системой контроля версий следит continuous integration сервер. Как только он замечает какие либо изменения, он делает checkout свежей версии и инициирует процесс сборки проекта.
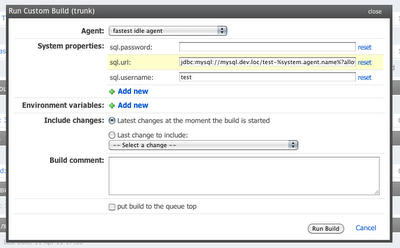
TeamCity позволяет очень детально настроить с какими параметрами будет запущен build. Вы можете предопределить значения системных переменных нужных вашему процессу билда. Эти переменные могут использоваться например для того чтобы специфицировать на какой БД будет выполнятся тестирование.
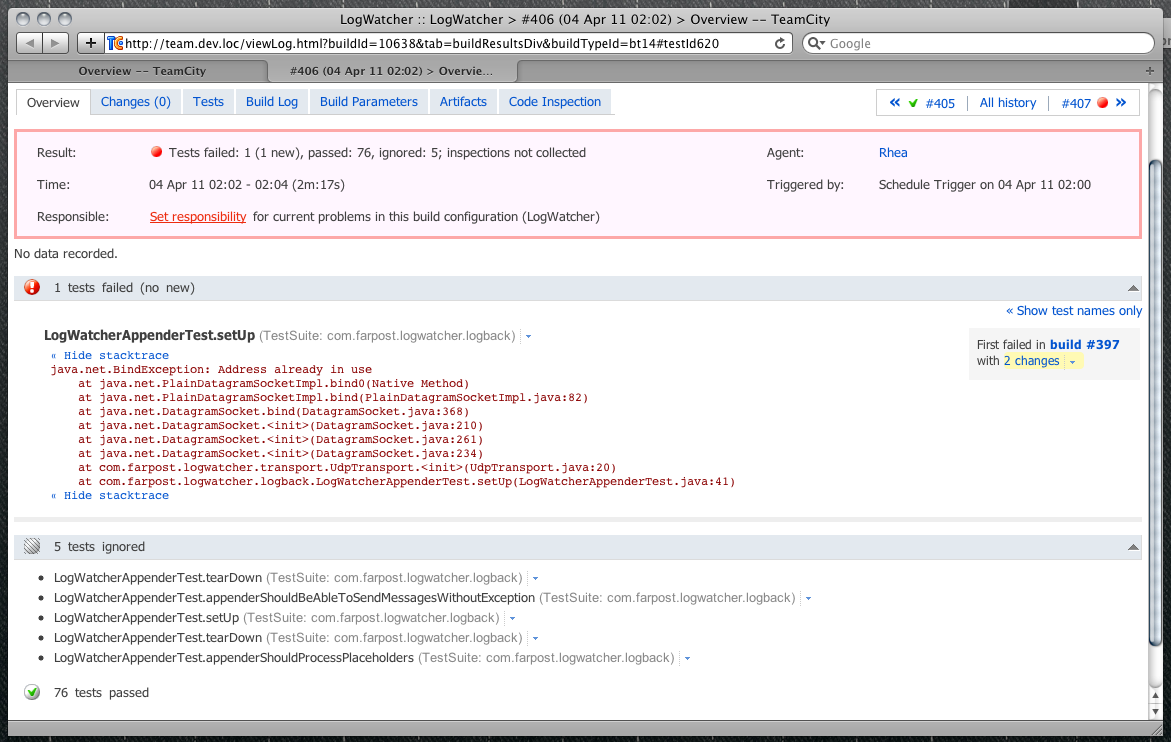
Затем в работу вступает Maven. Он компилирует исходники, запускает модульные тесты. Если они провалились, то генерирует отчеты по проваленным тестам, которые будут затем показаны на персональной странице билда, а сам билд завершается и считается проваленным:
Если тесты проходят, то “состав движется дальше”. Следующим шагом является сборка артефактов. В терминах continious integration артефакт это любой результат процесса сборки, главная черта которого — воспроизводимость. Для нас это означает что артефакт является процессом работы машины, а не ручных действий человека.
Обратите внимание, что в смежных областях знаний, например в configuration management, термин “артефакт” имеет немного отличные значения.
Воспроизводимость артефакта — очень важное его свойство. Оно позволяет в любой момент времени из любого среза VCS попытатся собрать приложение и посмотреть что из этого получится.
Воспроизводимость артефакта служит хорошей поддержкой для так популярных в наше время итеративных методов разработки, смысл которых состоит в идее “давайте начнем стрелять, а потом будем корректировать огонь”. Когда патроны дешевле чем время, это хороший подход. Налаженный процесс автоматического производства артефактов в этом контексте можно сравнить с автоматическим станком по производству патронов. Чем лучше он у вас отточен, тем дешевле ваши патроны, и тем быстрее вы можете стрелять и получать фидбек критически важный для следующей итерации.
После того как артефакт собран Maven принимается за интеграционное и приемочное тестирование. Здесь необходимо отметить зачем разделение между модульными, интеграционными и приемочными тестами.
Модульные тесты тестируют классы в изоляции от других частей системы, а также в изоляции от внешних систем, таких как базы данных и веб-сервисы. Их задача состоит в том чтобы давать программисту быстрый фидбек относительно того, работает система или нет безотносительно того верно ли она интегрируется с внешними источниками данных. Фактически, любой программист должен иметь возможность сделать checkout исходников проекта, запустить модульные тесты на абсолютно не подготовленной машине (например, без базы данных) и тесты должны выполнится. Единственная причина почему они могут не выполнится, это если в коде приложения допущена ошибка.
Таким образом, у модульных тестов не должно быть зависимостей, отличных от тех которые тест может удовлетворить сам. По личному опыту могу сказать: тех кто не соблюдаете это правило ждет не очень приятное будущее.
В сухом остатке. Модульные тесты должны:
- выполнятся быстро. Потолок 15-20 секунд, затем их просто перестают использовать. Здесь нужно обратить внимание на то, что модульные тесты должны выполнятся именно на стороне программиста и как можно чаще. И конечно же обязательно перед коммитом в систему контроля версий. На CI-сервере они выполнятся лишь для полноты тестирования;
- быть изолированными от внешнего окружения и выполнятся даже на машине без сети.
В отличии от модульных, интеграционные тесты проверяют как приложение дружит с внешними системами, и как следствие, обладают следующим рядом особенностей:
- могут требовать довольно сложное окружение для своего выполнения (конкретную БД, возможно даже конкретной версии);
- могут быть довольно медленными, так как включают в себя взаимодействие по сети, зачастую с системами производительность которых находятся под контролем третьих лиц;
- являются гораздо более хрупкими чем модульные, потому что опираются на заранее установленное окружение, а также на программное обеспечение которое скорее всего меняется без оглядки на ваше конкретное приложение.
Тем не менее тестировать все равно надо, поэтому такие тесты выделяются в отдульную группу и запускаются на CI-сервере. Настроить и поддерживать в актуальном состоянии сложное окружение проще один раз на сервере, чем десять раз на машинах разработчиков. Разработчик может запустить интеграционные тесты у себя, но для этого он должен настроить хотя бы часть окружения на своей машине, что может быть довольно непросто. Частично эти проблему можно решить при помощи виртуализации и таких инструментов как puppet.
Обычно интеграционные тесты на стороне разработчика запускаются только в случае если менялся интеграционный код системы и как правило только тесты на изменившуюся часть системы. С точки зрения maven (а именно, maven-surefire-plugin) интеграционные тесты отличаются от модульных только постфиксом (*Test у модульных, *IT у интеграционных). После того как тесту задан соответствующий постфикс, он автоматически начинает запускатся на нужной фазе сборки проекта.
Если с интеграционными тестами все хорошо, то запускаются приемочные. Приемочные тесты проверяют систему по типу черного ящика. Если вы разрабатываете web-приложение, то оно запускается на web-сервере и тест под видом обыкновенного пользователя начинает ходить по нему и проверять его работоспособность. Пожалуй, это один из самых сложных видов тестирования. В нем довольно легко наделать ошибок, которые могут существенно увеличить стоимость поддержки тестовой инфраструктуры. Это в конце концов делает процесс тестирования менее эффективным. Впрочем, тема приемочного тестирования выходит далеко за рамки моего поста, поэтому я не буду заострять на этом сейчас внимание. Людям искушенным очень советую прочитать книгу Джеза Хамбла и Девида Ферли Continuous Delivery.
Ну а мы отправляемся дальше. Следуюшая остановка — статический анализ кода. Мы используем findbugs для анализа кода. Статические анализаторы действительно находят ошибки и потенциальные уязвимости, так почему бы не делать это при каждом изменении наших исходных файлов.
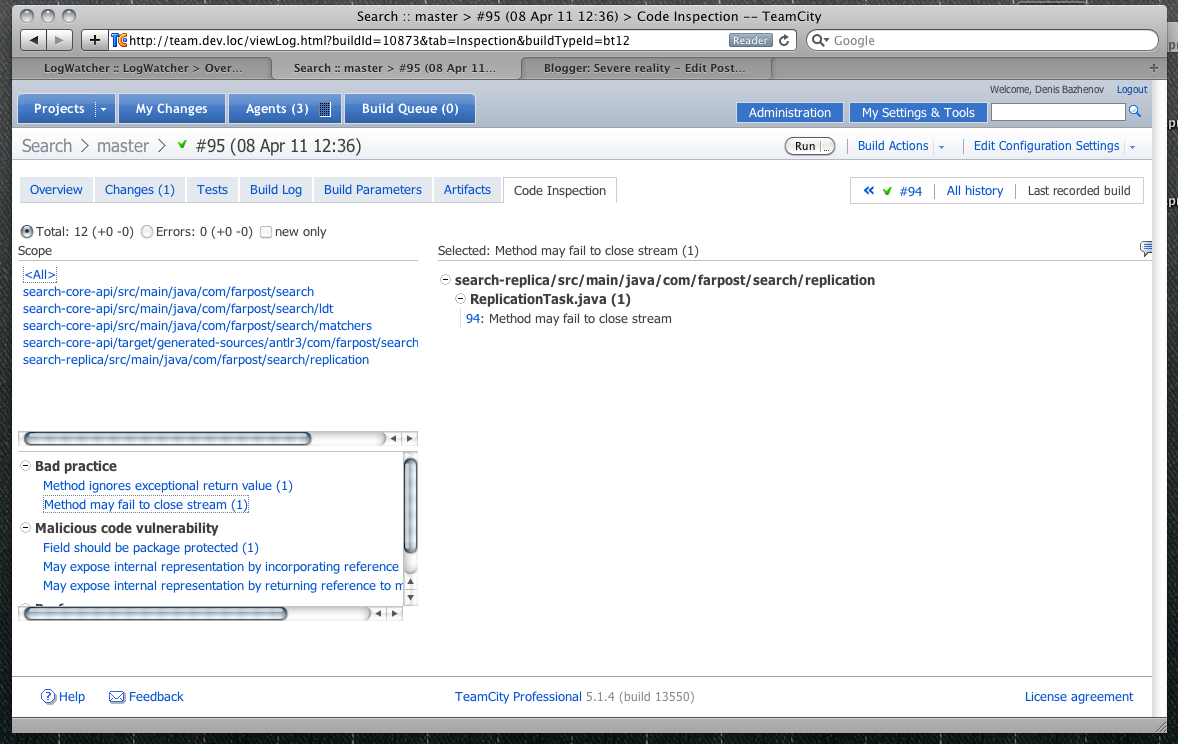
Можно указать TeamCity чтобы при превышении опредленного порога по количеству найденных проблемных ситуаций, билд считался проваленным.
Но, данный шаг можно порекомендовать не всем. Во-первых, для этого требуется существенная поддержка инструментов. Например, для php нет ничего подобного. Во-вторых, получаемая от статического анализатора информация должна оцениваться прагматически. Помните что анализатор показывает риски с формальной точки зрения. У каждого риска есть вероятность материализации и стоимость исправления. Вероятность материализации — это вероятность с которой риск превратится в проблему (то есть вы сможете наблюдать его воочию). Стоимость исправления — это сколько ресурсов (например, в виде человеко часов) нам надо будет потратить если риск все же материализуется в проблему. Перемножив эти два числа мы получим математическое ожидание проблемы. Может оказаться так, что математическое ожидание проблемы гораздо меньше чем стоимость внесения изменений в код здесь и сейчас. Некоторые проблемы дешевле исправлять пост фактум.
После того как статический анализ кода законечен, закончен и процесс непосредственно сборки. Теперь нам осталось опубликовать артефакт в общедоступный репозиторий и можно рапортовать об успешности билда.
Деплой у нас происходит в два этапа. Первый этап это деплой в локальный репозиторий артефактов. Второй этап включает в себя автоматическую доставку приложения на production сервера. Обратите внимание, доставку, но не deploy. Deploy осуществляется только по инициативе и под контролем разработчика. Таким образом, если разаботчик работает над проектом search-service версии 1.0 и на TeamCity успешно выполнился билд под номером 134, то на production кластере в папке проекта автоматически появляется файл search-service-1.0.134.war, который содержит в себе все необходимое для работы приложения и готов к развертыванию по команде разработчика. Это позволяет свести к минимуму участие человека в процессе билда. Человек привлекается только там где его внимание и возможность принимать решения не может заменить машина.
Вот пожалуй и все. Некоторые моменты остались за кадром. Например, как происходит запуск (deploy) приложения на production серверах. Но это тема совсем другого разговора.
Буду рад услышать отзывы и success stories читателей.