Раньше я уже писал о том, что нам приходится разрабатывать дополнительный инструментарий для себя. Еще одна сфера которую над которой мы плодотворно поработали — это логгирование. Здесь я не буду говорить о пользе логгирования и о том как надо логгировать. В интернете полно информации по этим аспектам. Я хочу рассказать о том, как мы анализируем логи.
Дело в том, что в сутки у нас генерируется порядка 100 мегабайт логов. Часть из этой информации — это информация об ошибках (при средней длине сообщения в 5 килобайт нам достаточно 4 секунд чтобы набрать мегабайт информации), часть это аудиторская информация. Просматривать такой объем информации в виде текстового файла — это просто нереально, поэтому мы создали для себя инструмент позволяющий аггрегировать информацию со всех компонентов системы и производить поиск по ней.
Компоненты системы посылают сообщения по протоколу UDP. UDP был выбран не случайно. Мы не хотим чтобы коллектор логов мог пагубно влиять на production приложение, поэтому мы специально выбрали такой протокол, который позволил бы не блокировать компоненты в случае, если коллектор медленно работает, или вообще отключен. Похожим образом работает syslog-ng, но мы решили все же “изобрести свое колесо”, чтобы иметь более изолированное решение и гибкость в определении протокола передачи данных.
В сообщениях которые генерируют компоненты находится следующая информация:
- тестовое сообщение;
- stacktrace exception’а (опционально);
- диагностический контекст (key-value набор аттрибутов).
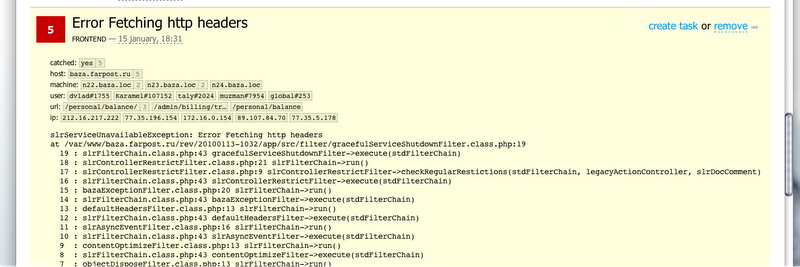
Это позволяет иметь следующий довольно удобный web-frontend, который предоставляет общую информацию о возникавших проблемах и аудиторских сообщениях.

Для каждого события есть severity (error/warning/info и т.д.), дата последнего возникновения, сколько всего раз происходило это событие, а также application id (символическое имя компонента приславшего сообщение).
По каждому отдельному сообщению можно посмотреть дополнительную информацию: stacktrace, а также диагностический контекст (на какой физической машине произошло событие, во время обслуживания какого клиента и т.д.).
Бывает так, что стандартных интерфейсов недостаточно. В этом случае есть поиск который позволяет найти какие-то специфические записи.
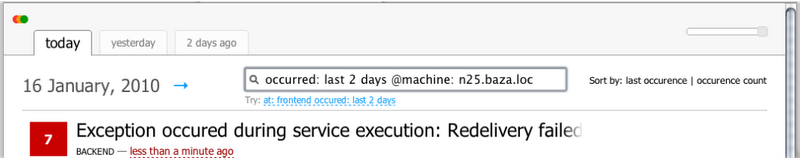
Поиск можно осуществлять по имени компонента приславшего событие, по дате и по всему диагностическому контексту. Приведу примеры некоторых запросов.
at: frontend severity: error— все ошибки произошедшие в компоненте frontend;occurred: last 2 days @user: bazhenov— все сообщения за последние два дня спровоцированные обработкой запроса для пользователя bazhenov;@machine: n25.baza.loc caused-by: slrDbConnectionFailedException— все записи пришедшие с сервера n25.baza.loc содержащие stacktrace exception’а типа slrDbConnectionFailedException.
Прямо здесь “на месте” из события можно создать тикет в нашей issue tracking системе. Вот так мы работаем с логами. А как вы следите за своими логами? :)