В прошлой заметке, я затронул тему порядка доставки сообщений MQ-системами. Отсутствие гарантий в отношении этого порядка вызвало некоторое возмущение со стороны читателей, поэтому я решил раскрыть эту тему более полно.
Почему же многие очереди сообщений не гарантирую порядок? И так ли он вообще важен — этот порядок доставки?
Почему многие системы очередей не гарантируют порядок доставки? Link to heading
Здесь потребуется договорится об обозначениях.
A и B запись A→B означает, что событие A происходит перед событием B. Людям знакомым с Java Memory Model эта запись должна быть известна как отношение happens-before.Давайте представим себе очередь сообщений, которая гарантирует вышеупомянутый порядок и двух подписчиков читающих сообщения из этой очереди.
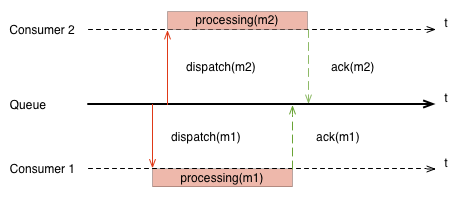
Исходя из этого мы можем определить порядок доставки сообщений следующим образом. Для двух любых сообщений m1 и m2 для которых выполняется условие receive(m1)→receive(m2) (то есть брокер получил сначала сообщение m1 потом m2), если гарантируется что dispatch(m1)→dispatch(m2), значит очередь сообщений гарантирует порядок доставки.
Тем не менее гарантия в отношении порядка доставки мало что дает. Даже если сообщения доставлены в порядке (in-order), consumer’ы могут обработать сообщения в порядке отличном от порядка доставки (out-of-order).
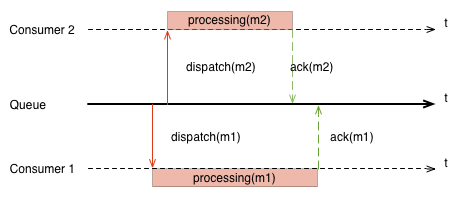
Как любит говорить один мой коллега: “Тому есть тысяча причин”. Машины на которых работают consumer’ы могут быть разной конфигурации: у них могут быть разные процессоры, разный объем памяти, разная по производительности подсистема I/O. Но даже если они идентичны, у вас нет контроля над детерминизмом cpu и I/O scheduler’ов. Любая машина может отказать или начать медленно работать из-за большого количества pagefault’ов и т.д. Все это говорит о том, что порядок доставки сообщений не имеет ничего общего с порядком их обработки. А ведь именно порядок обработки, а не доставки должен интересовать нас в первую очередь.
Порядок обработки сообщений мы можем определить следующим образом. Для двух любых сообщений m1 и m2 для которых выполняется условие receive(m1)→receive(m2), если гарантируется что ack(m1)→ack(m2), значит очередь сообщений гарантирует порядок обработки.
Но соблюсти это правило очередь сообщений может только одним способом. Путем форсирования порядка ack(m1)→dispatch(m2). Другими словами, брокер не должен отправлять следующее сообщение пока предыдущее не будет обработано. Это подразумевает следующую картину.
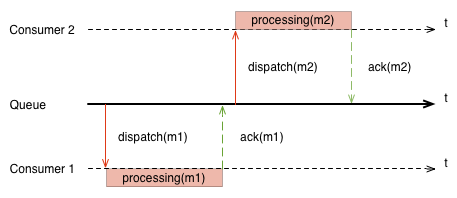
Не тяжело догадаться, что в любой момент времени в обработке будет находится только одно сообщение. В этом случае, пропускная способность кластера из десяти машин будет равна пропускной способности одной машины. Можете забыть про горизонтальное масштабирование.
Получается что порядок доставки сам по себе ничего не значит, — важен порядок обработки, предоставление гарантий в отношении которого убивает на корню пропускную способность.
А важен ли порядок порядок обработки? Link to heading
Иногда да. Есть ситуации когда порядок обработки очень важен. Предыдущая заметка иллюстрирует один из таких случаев. Но вы должны понимать, что любой порядок в web-приложении является имитацией. В любом web-приложении клиенты посылают запросы параллельно. Эти запросы параллельно идут по сети, параллельно обрабатываются frontend’ами, параллельно идут на backend’ы и так же параллельно ответы идут обратно к пользователям.
Место где порядок обработки начинает проявляться — это реляционная база данных. Если два потока в транзакции модифицируют одни и те же кортежи, база данных останавливает выполнение одного из потоков до тех пор пока другой не завершит свою работу. База данных линеаризует выполнение нескольких потоков таким образом, что в системе появляется порядок обработки. Но вместе с появлением порядка обработки испаряется пропускная способность. К тому же тот порядок который навязывает база данных может не совпадать с порядком поступления запросов на frontend. Для двух любых запросов req1 и req2 связанных порядком receive(req1)→receive(req2) соблюдение правила transaction(req1)→transaction(req2) не гарантируется.
В свою очередь, это означает что сложность, которая присуща решению продемонстрированному в предыдущей заметке, не является сложностью присущей асинхронным системам обработки сообщений. Это сложность присущая web-приложениям в целом. И даже если бы вы исключили MQ-систему из транка обработки и, скажем, посылали бы сообщения через SOAP или напрямую писали в базу данных, вам все равно пришлось бы реализовывать те же механизмы, чтобы обеспечить сохранность данных. Любое web-приложение — это конкурентная система в природе которой порядок обработки запросов отсутствует.
Некоторых людей такая ситуация не устраивает. Отчасти являясь идеалистами (что особенно характерно для программистов) они не могут ужиться с мыслью, что те или иные процессы протекают стохастично и не имеют порядка в своей природе. Попытки навязать этот порядок обрекают web-приложение на деградацию пропускной способности. Вы можете наблюдать этот синдром повсюду — начиная от многопоточного программировния и использования mutex’ов до баз данных и протоколов XA-транзакций. В свое время Dan Pritchett написал об этом отличное эссе — “Chaotic Perspectives”.
Если вы web-программист, то я вас поздравляю. Судьба сделала вам подарок. В других отраслях программистам приходится прилагать титанические усилия для распараллеливания задач. У вас же большая часть процессов протекает и так параллельно. Все что вам надо, — смирится с мыслью, что порядок обработки запросов в системе не детерминистичен. С этим бессмысленно бороться, этим надо уметь пользоваться.