Существует одна очень старая и эффективная техника — конвейерная обработка данных (pipelining). Ее смысл заключается в том, что разные физические исполнители, которые могут работать не блокируя друг друга (хвала DMA), такие как: процессоры, жесткие диски, сетевые карты, — должны работать не блокируя друг друга. Это позволяет повысить их утилизацию, и, если правильно все организовать, не допустить перегрузки отдельно взятых исполнителей. Отличительной особенностью этой техники является то, что она используется в микропроцессорах с незапамятных времен, и сейчас является неотъемлемой частью любого суперскалярного процессора.
Представьте себе следующий код:
while ( !isInterrupted() ) {
byte[] data = performComplexIOOperation();
performComplexProcessing(data);
}
Довольно типичная ситуация. Сначала мы читаем данные, потом обрабатываем. Если каждая из фаз (чтение/обработка) в отдельности требует много времени, то этот код не сможет полностью утилизовать ни процессор ни подсистему ввода/вывода. Что мы можем сделать для того, чтобы более полно утилизовать ресурсы машины, на которой работает приложение?
Давайте посмотрим на то, чем занимается наш поток выполняющий этот код.
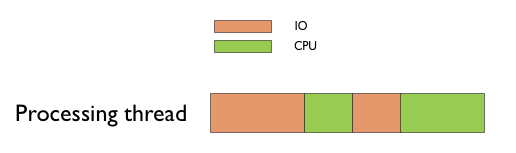
Вполне очевидно, что ни IO, ни CPU не загружены на 100%. Причиной является то, что один поток работает сразу с двумя физическими исполнителями, не давая возможности этим исполнителям работать параллельно. В тот момент, когда процессор обрабатывает данные, жесткому диску нечем заняться. Пока жесткий диск читает данные, у процессора нет работы. Вы можете сказать: “Так ведь процессор не просто ждет. Он ждет данных от жесткого диска”. Все верно, но чего ждет жесткий диск пока процессор обрабатывает очередную порцию данных?
Это приводит нас к следующим двум правилам:
- поток занимающий процессор не должен иметь причин для блокировки;
- поток не занимающий процессор может иметь только один ресурс, который может служить причиной его блокировки (конечно все иначе, если вы используете какую-либо из моделей неблокирующего ввода/вывода).
Другими словами, поток управления должен работать только с одним исполнителем. Можете это считать принципом единичной ответственности для многопоточного программирования.
Мы можем вынести чтение в отдельный поток и связать потоки при помощи очереди задач.
class ReadingThread implements Runnable {
private final Queue<ByteBuffer> queue;
[...]
public void run() {
while ( !isInterrupted() ) {
queue.add( performComplexIOOperation() );
}
}
}
class ProcessingThread implements Runnable {
private final Queue<ByteBuffer> queue;
[...]
public void run() {
while ( !isInterrupted() ) {
ByteBuffer buffer = queue.poll();
performComplexProcessing(buffer);
}
}
}
В этом случае картина будет выглядеть примерно следующим образом.
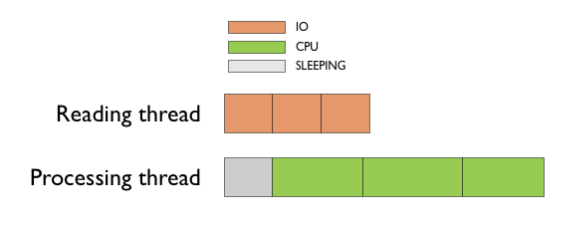
Теперь мы имеем загруженный жесткий и один загруженный процессор. Что мы можем сделать еще?
Если задача обработки хорошо распараллеливается, то мы можем делегировать обработку данных не отдельному потоку, а пулу потоков. Тем самым мы можем утилизовать несколько процессоров.
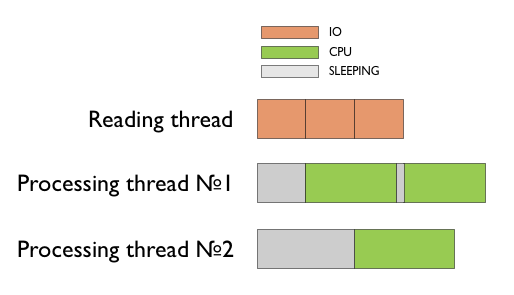
Стоит отметить, что java предоставляет все необходимые синхронизационные примитивы для реализации конвейерной обработки данных, такие как: конкурентные очереди и пулы потоков.
Закрепление за отдельным исполнителем отдельного потока дает ряд преимуществ:
- не имея других причин для блокировки кроме как на этом исполнителе, мы способны утилизовать его полностью. По-крайней мере, до тех пор пока коммуникационный механизм (например, очередь при помощи которой передаются данные между потоками) не станет bottleneck’ом;
- так как не существует большого количества потоков работающего с исполнителем мы не допускаем его перегрузки.
Второй аспект очень важен. Вы должны понимать, что большое количество потоков вредит системе. В случае процессора это высокий context switch’инг, что пагубно влияет на производительность. В случае жесткого диска мы можем забыть про sequential read.
Стоит отметить, что коммуникация между потоками не может быть бесплатной. Не смотря на то, что существуют довольно эффективные алгоритмы для реализации неблокирующих очередей, делегировать сложение двух чисел в отдельный поток все же не стоит. Коммуникационные расходы будут дороже, чем выполнение задачи.