Начиная с 70-х годов прошлого века производители микропроцессоров осуществляли экспоненциальный рост производительности, описанный законом Мура. Но достигнув физических ограничений, связанных с резким скачком тока утечки транзисторов и, как следствие, рассеивания тепла, стало понятно — дальнейшее увеличение производительности процессоров существующими техниками невозможно. Еще в 2003 году Intel обещала предоставить 4 ГГц модель. И вроде бы годом позже Intel’овцы приблизились к реализации задуманного, — появился процессор с тактовой частотой 3.8 ГГц. Но 4 гигагерцовым “мечтам” так и не суждено было сбыться. А все современные модели процессоров работают на тактовой частоте до 3 ГГц. Индустрия, как мы все теперь знаем, пошла другим путем. Выходом стало увеличение количества процессоров (ядер).
Причем, мне кажется, что Intel давно предвидела что дни гигагерцовых гонок сочтены. Hyper-Threading тому доказательство. Эта технология изначально появилась в архитектуре Xeon, но позже была реализована и в Pentium 4. Это был первый сигнал нам разработчикам, — учитесь распараллеливать. Затем появились многоядерные процессоры. А теперь, Anwar Ghuloum, ведущий инженер Intel, открыто просит разработчиков учитывать особенности SMP архитектуры.
developers should start thinking about tens, hundreds, and thousands of cores now in their algorithmic development and deployment pipeline1
Халява кончилась. Дальнейший рост производительности возможен, только путем изменения существующих алгоритмов и их распараллеливания. И именно нам разработчикам придется поставить все эти ядра на службу человечеству. Это и имеют в виду, когда говорят, что наступил конец эры закона Мура.
Справедливости ради надо отметить, что технически закон Мура все же будет выполняться, так как он предсказывает экспоненциальный рост числа транзисторов в интегральный микросхемах. Однако экспоненциального роста производительности при этом наблюдаться не будет. Как такое может быть? На этот вопрос отвечает преемник закона Мура, который и будет вершить бал с этих пор, — закон Амдаля.
Возьмите любую привычную для вас задачу. Если вы заняты в сфере разработки web-приложений — это может быть обработка пользовательского запроса. Представьте, что вы обрабатываете пользовательские запросы в разных потоках (я предполагаю, что так оно и есть). В любом, случае у этих потоков есть, так называемые, точки сериализации. Это участки кода, которые не могут быть выполнены параллельно. Например, некоторые операции в базе данных при использовании транзакций не могут выполнятся параллельно. Shared lock’и и многие виды координации потоков являются точками сериализации. Именно они, — эти противные точки сериализации, являются причиной того, что производительность системы падает при увеличении количества исполняемых потоков.
Попробуйте прикинуть какой процент вашего кода не может выполнятся параллельно. Назовем эту величину нормированную по единице фактором сериализации — P. Отбросим пока издержки на синхронизацию памяти. Если фактор сериализации равен 1, то вы не можете ничего распараллелить. Даже появление сотни ядер не ускорит вашего приложения. Если фактор сериализации равен 0, то появление ста ядер ускорит ваше приложение в сто раз (либо позволит решать одновременно сто таких задач). Зная свой фактор сериализации вы можете посчитать, на какой теоретический прирост в производительности (speed up factor), вы можете расчитывать, если в системе будет не одно ядро, а N. Посчитать это очень легко.
$$\frac{ 1 }{ (1-P)+\frac{P}{N} } $$
Не знаю во сколько вы оценили свой фактор сериализации, но у меня для вас плохие новости. Даже если вы его оценили в 0.1 (10%) — это означает, что вы перестаете эффективно масштабироваться примерно на 10 процессорах (прирост производительности от дальнейшего добавления исполнителей составляет меньше 50% от теоретически возможного).
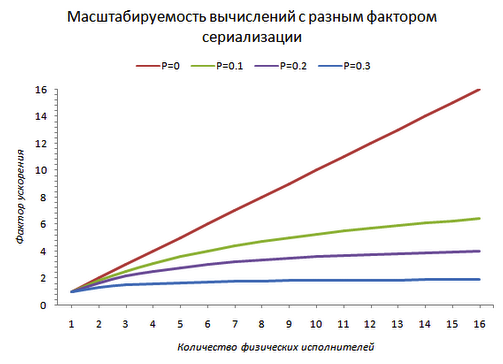
При факторе 0.5 (половина вычислений) добавление пятого процессора в систему ускорит ее максимум на 6% по-сравнению с четырех-процессорной. Говорить об эффективном использовании 8-процессорной машины не приходится. А ведь попадаются очень выдающиеся сервера.
С другой стороны, если взглянуть на каждый отдельно взятый процессор/ядро, то с ростом фактора сериализации его загрузка начинает падать.
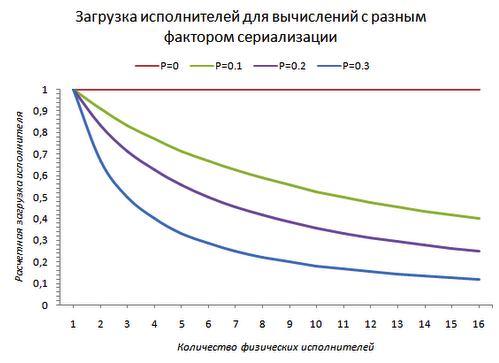
Происходит это по вполне понятным причинам. Из-за того, что в системе присутствует точка сериализации, которую по-определению может выполнять только один поток, другим потокам в это время просто нечем заняться.
Это немного иронично, но на dedicated серверах из-за этого встает проблема, — как загрузить CPU работой. А выглядит это так. MySQL в какой-то момент времени перестает обрабатывать запросы (делает это очень медленно). Вы заходите на сервер, а там все в порядке: CPU не загружен, памяти свободной куча, i/o в порядке. Но запросы обрабатываются крайне медленно.
Но нет худа добра. Я верю, что мы со временем создадим эффективные и что еще более важно, удобные механизмы для распараллеливания задач. Они уже начинают появляться. У бизнес сектора начинает просыпаться интерес к кластерным вычислениям, что подтверждается появлением таких платформ как Amazon EC2/S3 и Java Stax. Появляются новые языки и инструменты, такие как Scala и Kilim, которые позволяют эффективно работать с concurrency. Получают более широкое распространение уже знакомые методики функционального программирования, которые очень помогают в данном случае. А это все говорит о том, что у нас с вами есть огромное поле для развития и самосовершенствования, чего я вам и желаю.